2016_Rethinking the Inception Architecture for Computer Vision(CVPR2016)_SzegedyC et al
一、背景及意义(动机)
虽然在有足够标签数据的前提下,通过增加模型的大小和计算代价可以马上带来性能的提升,但是足够快的计算效率和更小的模型仍然对于某些场景很重要,比如移动端的视觉识别任务和大数据场景。Inception网络结构的提出正是为了能够找到一个运行效率高、性能高且模型复杂度较小的网络结构,但是Inception体系结构的复杂性使得在该网络上再做一些优化变得很困难,因为改变里面的一些结构有可能会带来性能的快速下降。之前也没有解释网络结构中哪些构建原则对网络性能影响比较大,这样更加难以对其进行调整。在这篇论文中,作者首先提出了一些关于如何有效去扩大网络结构来获得更多性能提升的通用原则;然后作者根据这些原则通过适当的卷积分解和有效的正则化来尽可能有效地增加模型表达能力,并以此按比例增加网络,来找到一个更加精简有效的网络结构。最后作者在ILSVRC2012分类比赛的验证集上对模型进行测试,并达到了最先进水平。在单模型单帧测试的情况下,该模型仅以50亿次加乘操作的代价,达到了top-1误差为21.2%,top-5误差为5.6%。模型仅有两千五百万参数。通过4个模型以及multi-crop的方式进行测试,更是将top-5误差减少到3.5%,top-1误差减少到17.3%。
二、使用什么方法来解决问题(创新点)
2.1 创新点
- 提出了网络结构通用的设计准则(这些原则的应用并不十分明确,只是指明了一个方向)
- a. 应该避免表示瓶颈,特别是在网络前几层。网络的表达能力不能一下子被过度压缩,而应该从输入到输出逐渐地减小。而且理论上,模型的表达能力不能仅仅通过维度来衡量,其它因素如相关的结构之类也是很重要的因素,维度只是提供了表达能力的粗略估计。
- b. 在网络较深层应该利用更多的feature map,有利于容纳更多的不相关的特征。这样可以加速训练。
- c.大的卷积,可以通过多个小卷积的聚合来表示,即把卷积稀疏化,并且不会降低表达能力。
- d.要平衡网络的宽度和深度。同时增加网络的深度和宽度可以带来准确率的增加,但是适当的比例可以带来最大的提升。
- 提出了对卷积进行分解但不降低表达能力的方法。
- 提出了有效的正则化方式。
- 结合分解卷积及有效的正则化,找到精简但是性能强大的网络结构。
2.2 重要结论
- 可以将卷积分解为非对称卷积,而不降低表达能力。
- 在feature map大小为12到20之间的卷积层使用1x7和7x1的对称卷积,效果非常好。
- 辅助分类器不能辅助模型拟合,更多是作为一个正则项的功能。
- 应对低分辨率的情况,最好是通过调整stride和maxpool来让网络适应低分辨率,而不是使用小网络。
三、方法介绍
3.1. 卷积分解
3.1.1 利用两个3X3卷积来替代一个5x5的卷积
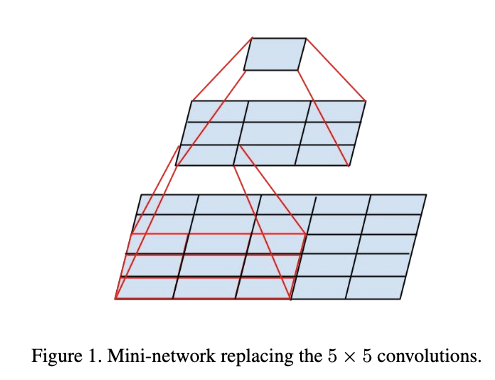
这种替代方式在保持感受野不变的情况下,带来了计算量以及参数量的减少。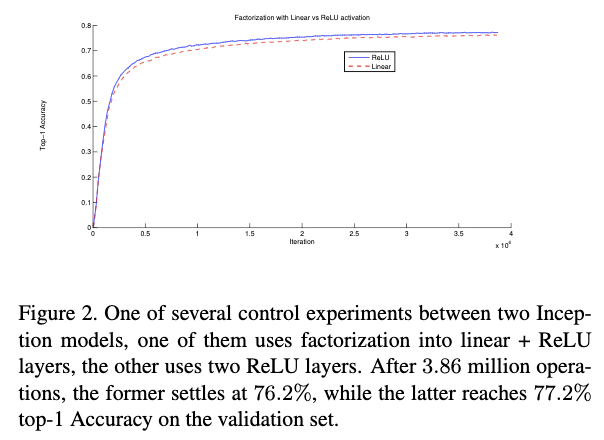
这种替代方式使用线性激活函数应该更加吻合,但是作者做了对比试验发现,Relu要比线性激活函数效果要好。使用Relu增加了模型的表达能力。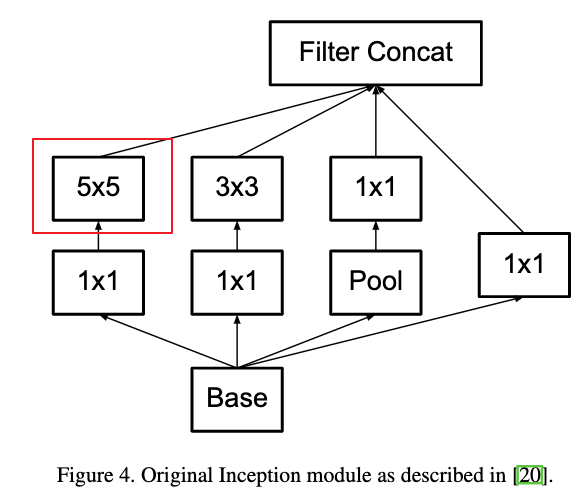
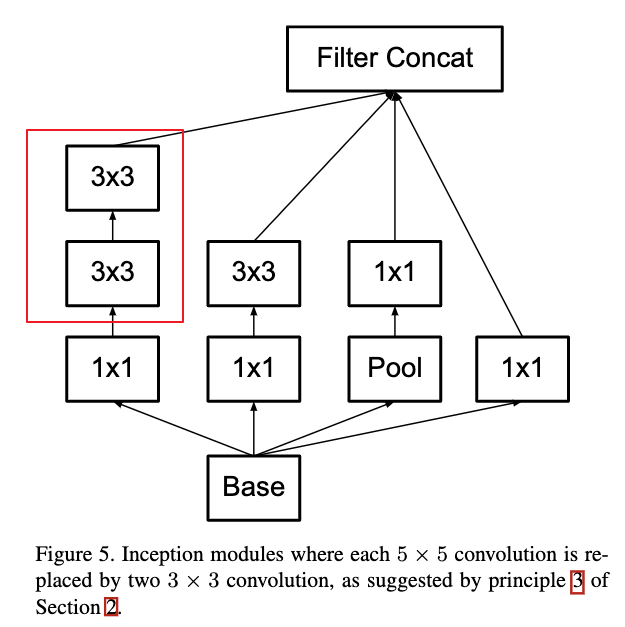
Figure 4和Figure 5给出了利用两个3X3卷积来替代一个5x5的卷积的例子。
3.1.2 将卷积分解为非对称卷积
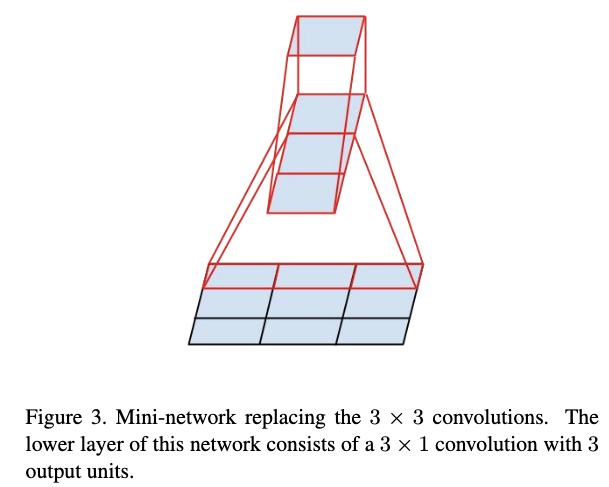
可以用两个3x1和1x3的不对称卷积来替代3x3卷积,进一步降低参数量及计算量,同时也增加了非线性性。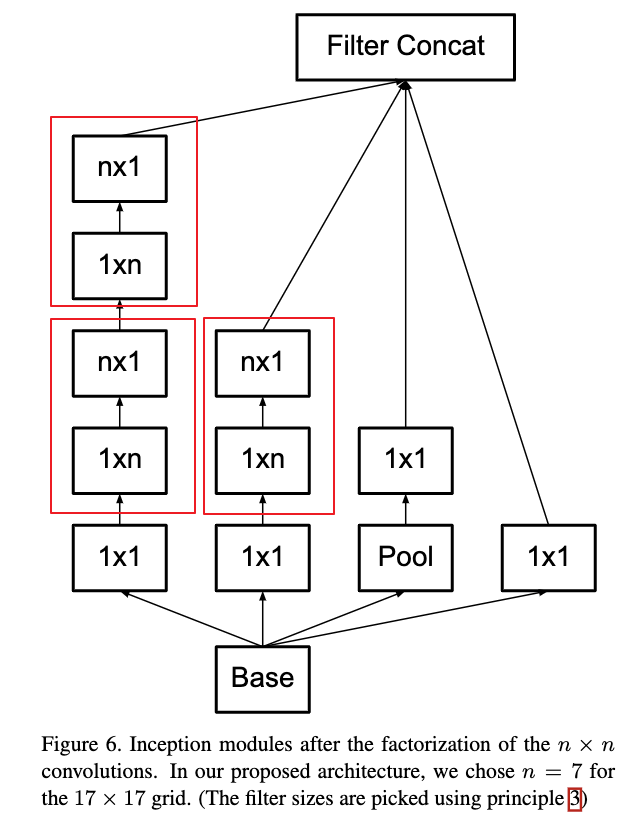
理论上可以用nx1和1xn来替代任何大小的nxn卷积,如Figure 6所示,但是作者发现实际应用中,在浅层卷积层使用效果并不好,但是在中等大小的feature map(在feature map大小为12到20之间的卷积层)上使用效果比较好。在feature map大小为12到20之间的卷积层使用1x7和7x1的对称卷积,效果非常好。在作者提到的网络结构中,作者在17X17大小的feature map上,使用了1x7和7x1分解卷积。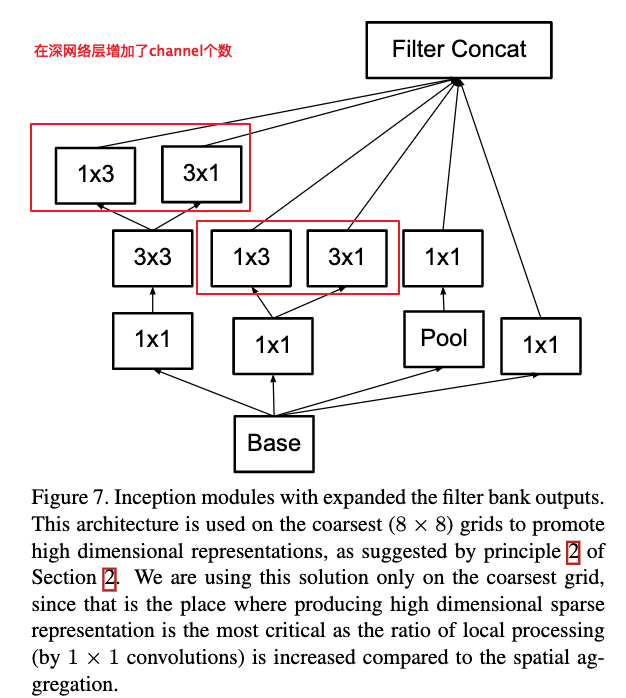
Figure 7给出了增大网络宽度的一种方式。在作者提到的网络结构中,作者将其应用到了feature map大小为8x8的卷积层,为了增加高纬的特征表示,这个也是原则2所建议的方式。
3.2 辅助分类器的使用
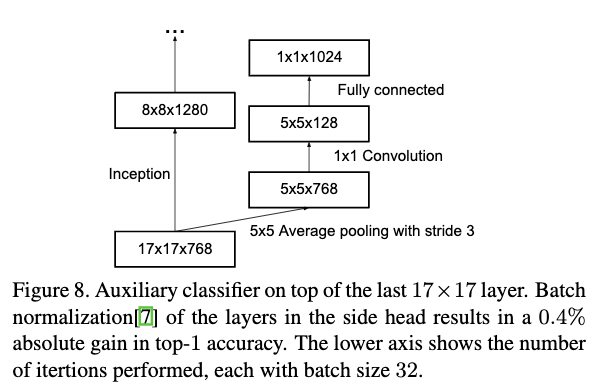
辅助分类器是在《Going deeper with convolutions.》中提出来的,作者说使用辅助分类器可以加速拟合,缓解梯度消失。但是本文作者发现辅助分类器并没有这个效果。作者发现:
- 在模型没有达到完全拟合之前,使用辅助分类器或者不使用辅助分类器拟合速度都是差不多的。只有在模型接近拟合的时候,使用辅助分类器会比没有使用辅助分类器模型的准确率会更高一些。
- 在《Going deeper with convolutions.》中作者使用了2个辅助分类器,但是本文作者发现,将底层的辅助分类器移除掉,对模型最终的效果并没有影响。
所以先前说辅助分类器可以辅助模型拟合的说法是有问题的,在这里辅助分类器更多是作为一个正则项的功能。这个也有一些证据的支持,就是在辅助分类器使用bn,或者dropout时,模型表现会更好。
3.3 feature map大小的有效减少
为了降低Feature map的大小,通常都会使用pooling操作。为了避免表示瓶颈,在pooling之前会先用卷积对filter进行扩展,然后再应用max或者avg pooling操作。比如想要从大小为dxd,通道数为k的feature map过度到大小为(d/2)x(d/2),通道数为2k的feature map,一种没有表示瓶颈的操作方式是先利用stride为1的卷积层,先得到一个通道数为2k的feature map,然后再应用pooling操作,但是这种方式会增加计算代价。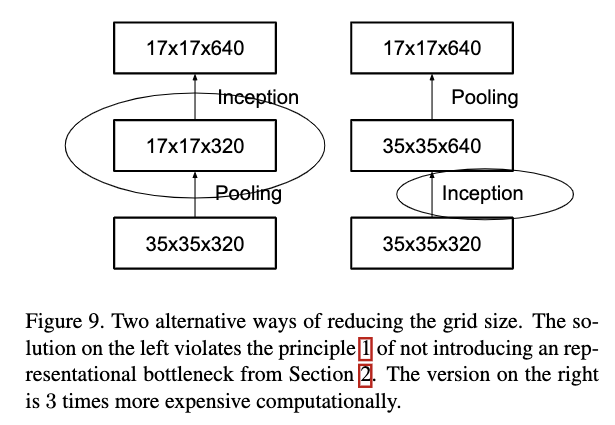
如Figure9左边所示,先pooling再卷积会带来表示瓶颈;如Figure 9右边所示,先卷积再pooling会增加计算代价。
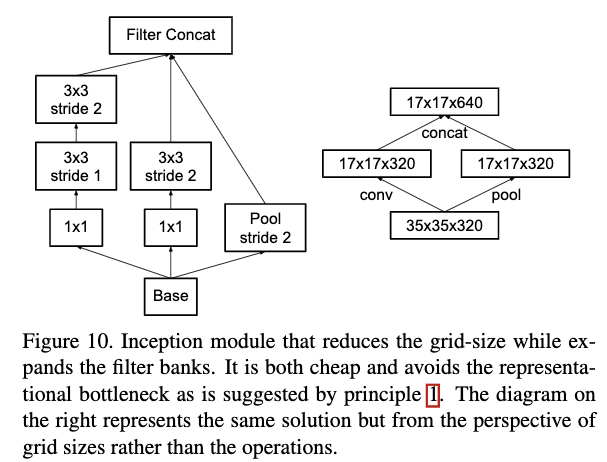
为了既能解决表示瓶颈又不会增加计算量,作者提出了一个新的构建模块。使用两种stride为2的并行分支,一种是先进行pooling,一种是进行卷积,然后再将两者拼接。如Figure 10所示,这种方式能在减少feature map大小的同时增加filter大小且不会带来表示瓶颈也不会增大计算代价。
3.4 Inception-v3
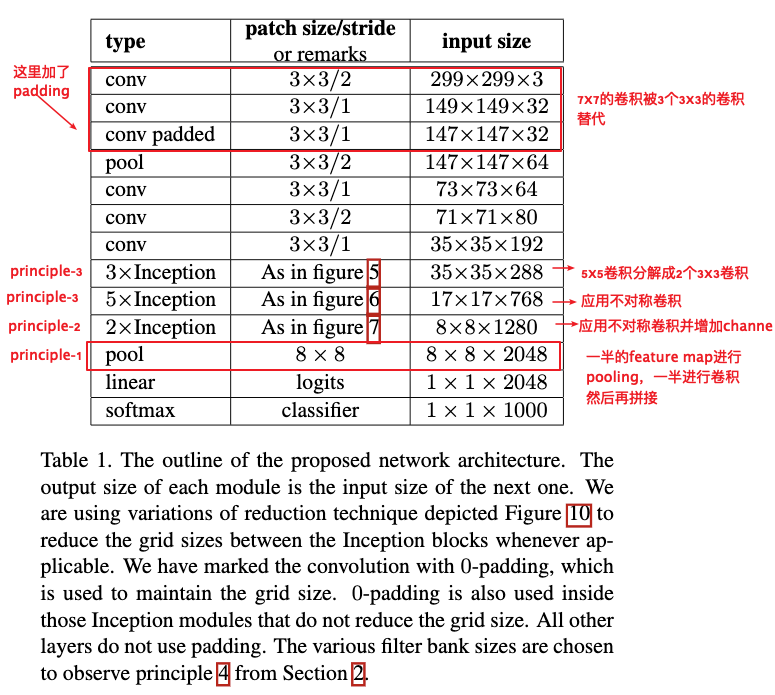
作者根据提到的原则构建了网络模块,并使用这些原则下的构建块提出了一个新的网络结构。详细的网络结构设置如Table1所示。改进的Inception结构计算代价仅比GoogleLeNet大2.5倍,但是仍然比VGGNet代价小。
3.5 通过标签平滑进行模型正则化
这里作者对标签的分布进行平滑,以此让模型预测出来的概率差异不至于太大。如果预测出来的概率在真实标签位置接近于1,而其它标签位置接近于0,这样的话很容易过拟合而导致泛化能力较差;另外当预测出来的真实标签的概率远远大于其它标签概率的时候,这样产生的梯度就比较小而使模型的适应能力差,最终导致模型泛化能力较差。作者提出的方法是为标签加入一个平滑正则项(LSR),该平滑正则项为均匀分布,直觉上是让模型预测出来的概率值更偏向于均匀分布一些。加入正则项的ground truth可表示为: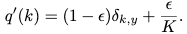
这里K为类别数,而$\epsilon$为权重。通过加入该正则项,最终作者提到的模型在ILSVRC2012分类任务上,top1-error和top5-error性能都提高了0.2%
3.6 训练细节
- 使用随机梯度下降,50张Kepler GPU,每张卡batch size 32,跑100个epoch.
- 使用RMSProp优化方法,decay 为0.9,$\epsilon$为1.0.
- 初始学习率为0.045,使用指数衰减方式,每2个epoch衰减一次,底数为0.94.
- 作者发现使用梯度截断能够让训练更加稳定,这里作者使用的阈值为2.0.
3.7 分辨率对性能的影响
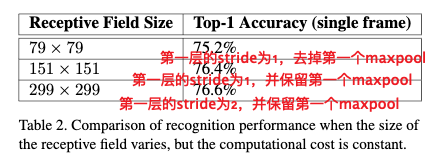
作者在保持计算代价的情况下,比较了不同分辨率输入的效果。发现低分辨率会略微影响性能,但是影响不大。如果在低分辨率的情况下也减少模型复杂度,那性能会降得更多。所以最好是通过调整stride和pooling来让模型适应低分辨率的情况。
四、实验结果

Table3为单模型单crop下的结果。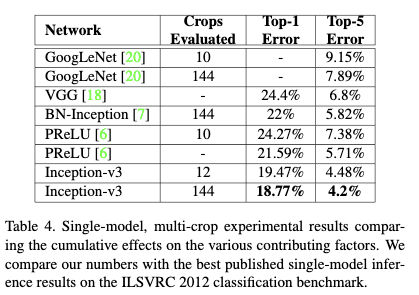
Table4为单模型多crop下的结果。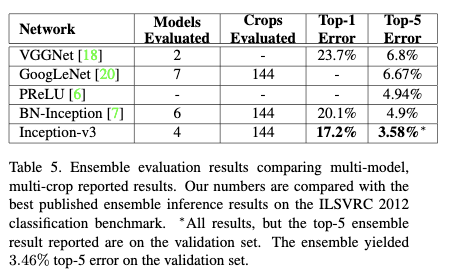
Table5为多模型多crop下的结果。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2016_Rethinking the Inception Architecture for Computer Vision(CVPR2016)_SzegedyC et al
文章字数:2.5k
本文作者:xieweihao
发布时间:2017-01-20, 13:18:55
最后更新:2020-01-23, 10:12:44
原始链接:http://weihaoxie.com/post/15020972.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

