2017_ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices_CVPR2017_ZhangX et al
一、背景及意义(动机)
作者发现Xception和ResNeXt在网络比较小的情况下,由于存在大量的1x1卷积使得网络的效率不高。为此作者在这篇论文中提出使用1x1的分组卷积来降低1x1卷积的复杂度。为了消除分组卷积带来的负面影响,作者提出了一个新颖的处理方式,对分组卷积通道进行shuffle。基于这两个技术,作者提出了一个专门为移动端设计的CNN网络结构,ShuffleNet。这两个技术使得提到的网络结构可以在维持准确率的情况下极大的减少计算量。相较于其他同等复杂度的网络结构,shuffleNet可以使用更多的通道来编码更多有用的信息,这个对于非常小的网络的性能是很关键的。作者在ImageNet分类任务和COCO目标检测任务上验证了该方法的有效性。特别是在ImageNet分类任务上,在计算量为40MFLOPs的情况下top-1误差要比MobileNet低7.8%。在基于ARM的设备上,提到的网络结构在维持跟AlexNet同等准确率的情况下,速度要比AlexNet快大约13倍。
二、使用什么方法来解决问题(创新点)
- 提出使用1x1的分组卷积来降低1x1卷积的复杂度并通过对分组卷积通道进行shuffle来消除分组卷积带来的负面影响(即分组卷积组间信息的关系没能很好的学习到)。
- 提出了更适合于小网络的ShufflNet unit
三、方法介绍
3.1 Channel Shuffle for Group Convolutions
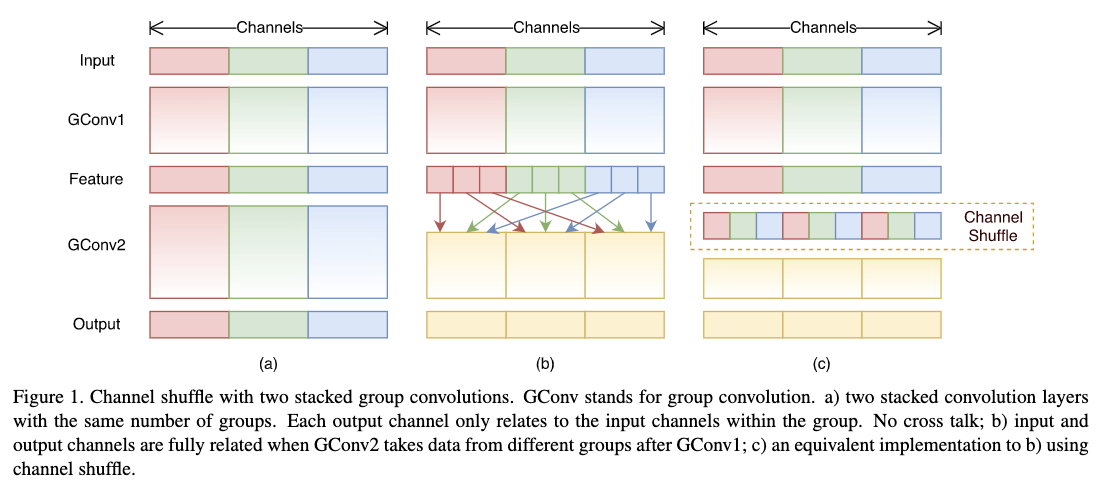
作者发现现在主流的网络结构,如Xception和ResNeXt,没有考虑对1x1卷积进行优化设计,但是1x1卷积在整个网络中占据的计算量是很大的。为此作者采用分组卷积对其进行优化,分组卷积可以大大降低1x1卷积的计算量。但是当多个分组卷积堆在一起的时候会出现一个问题,就是下个分组卷积中每个组有可能只用了上个分组卷积里面同个组产生的结果,Figure1(a)阐明了这种情况。为了避免这种情况,可以让下个分组卷积的输入来自于上个分组卷积的各个分组的结果,如Figure1(b)所示。这种方式可以通过通道shuffle操作来实现,如Figure1(c)。通道shuffle操作其实很简单,假设有$g$个分组的卷积层,则其输出的通道数为$g\times n$;那么通道shuffle操作是先将输出的通道维度reshape成$(g,n)$,然后将其转置再展平。这个操作在前后两个分组卷积的组数不同的情况下也是适用的,而且该操作也是可微的,能够进行端到端的训练。
3.2 ShuffleNet unit
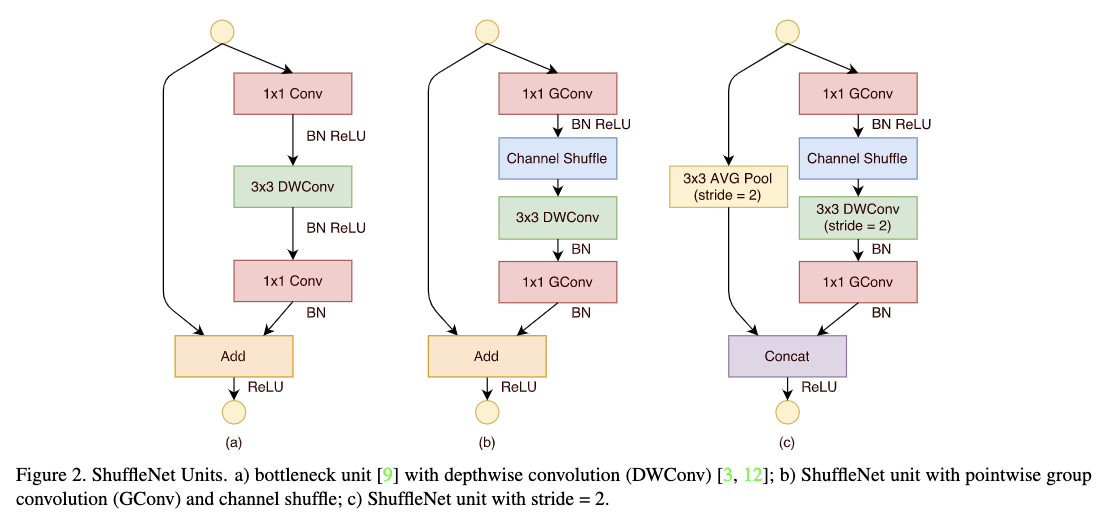
Figure2给出了ShuffleNet unit结构,该结构主要是在resnet unit的bottlenet形式上加入了逐通道分离卷积、1x1分组卷积以及通道shuffle操作。Figure2(a)为加入逐通道分离卷积的bottleneck unit;Figure2(b)为ShuffleNet unit;Figure2(c)为stride=2的ShuffleNet unit。
3.3 网络结构
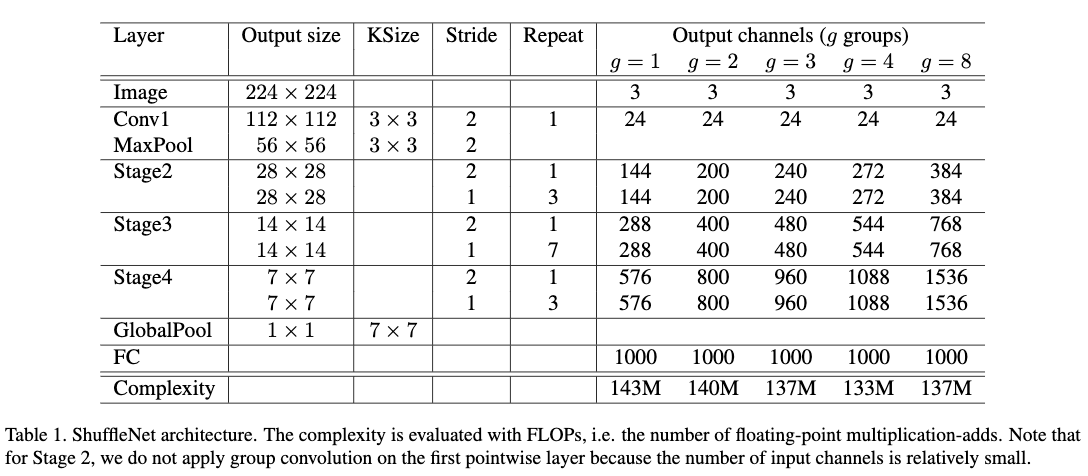
Table1给出了ShuffleNet的网络结构。这里每个ShuffleNet unit中bottleneck通道是输出通道的四分之一。stage2的第一个shuffleNet unit,作者没有使用1x1的分组卷积,因为网络的通道数比较小,而是适用了加入逐通道分离卷积的resnet的bottlenet形式。Table1给出的是复杂度为1的ShuffleNet版本,即为ShuffleNet 1x,其它复杂度可以通过减少通道数据来得到,比如shuffuleNet sx,可以将通道数乘以s倍。
四、实验结果
作者使用ImageNet2012分类数据集来验证提到的网络结构的有效性。具体参数设置可以参看原文。
4.1 Ablation Study
4.1.1 使用分组的1x1卷积对模型性能的影响
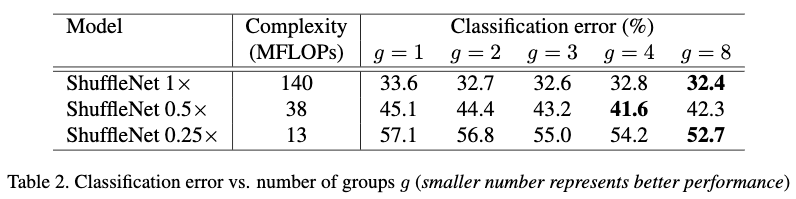
Table2对比了3个不同尺度,每个尺度不同分组的效果。g=1为不使用1x1的分组卷积的情况。从Table2中可以看出使用1x1分组卷积要比不使用分组卷积效果要好。另外由于组数越多可以产生的特征图也越多,也可以看出特征图越多的情况下效果越好。但是当分组达到一定程度的时候,由于输入的通道数变少也会影响效果。所以这两方面应该进行权衡。
4.1.2 使用通道shuffle对性能的影响
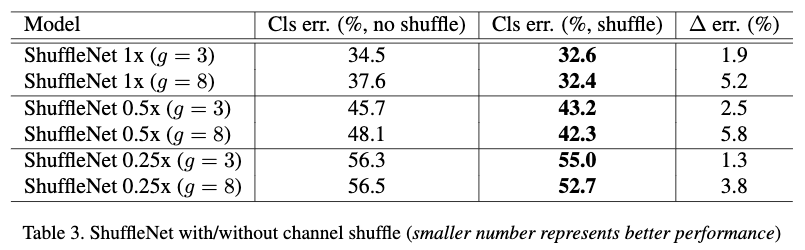
Table3对比了3个不同的复杂度下,使用通道shuffle和不使用通道shuffle的性能。从Table3可以看出使用通道shuffle要比不使用效果要好,特别是当组数比较大的情况下,效果更明显。
4.2 不同网络结构单元的对比

作者按照VGG,ResNet,Xception,ResNeXt的设计思想,重新设计了对应的小网络版本。从Table4可以看出相同复杂度下,提到的网络结构要比其他设计单元要好。
4.3 与MobileNets及其他框架进行对比
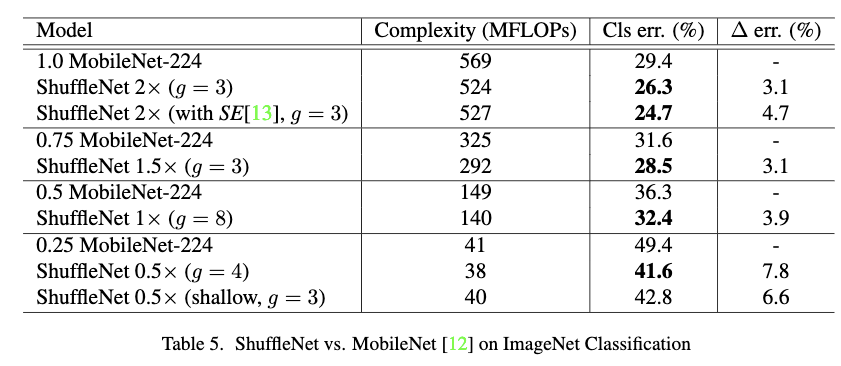
MobileNet是专门为移动设备设计的网络,他在小模型层面取得了最先进的结果。Table5给出了ShuffleNet和MobileNet在分类任务上的对比结果。可以看到在同等复杂下,ShuffleNet效果都比MobileNet要好。虽然ShuffleNet原本是设计成小模型的,但是它在网络复杂度较大的情况下也超过过了同等复杂度的MobileNet。另外作者也对比了ShuffleNet和MobileNet在同等深度下的结果,ShuffleNet仍然要比MobileNet好,说明增加的性能不是仅深度带来的,而更多是ShuffleNet Unit。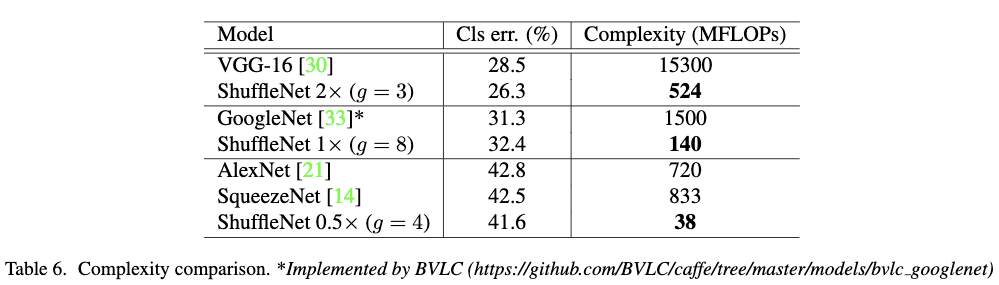
Table6作者对比在相同的准确率下,主流框架与ShuffleNet的复杂度。可以看出在同等准确率下,ShuffleNet的复杂度要远远小于其他主流模型。
简单的网络结构设计也使得ShuffleNet很容易结合最新的一些成果,比如Squeeze-and-Excitation模块。从Table5中可以看出,通过组合SE模块,top-1误差降低到了24.7%。虽然SE模块增加了很小的网络复杂度,但是在移动端运行速度却要慢上25%到40%。这说明网络结构的设计对于移动端的速度是很关键的,不仅仅是模型的复杂度。
4.4 模型在目标检测任务上的效果

作者采用faster rcnn框架去测试提到的模型在COCO目标检测任务的效果。作者使用COCO trainval-113k作为训练集,val-5k作为验证集。Table7给出了两个不同分辨率下MobileNet和ShuffleNet在COCO目标检测任务上的效果。ShuffleNet 2x与MobileNet具有相同的复杂度,从Table7可以看出ShuffleNet 2x在COCO目标检测任务上要比同等复杂度的MobileNet效果要好;而ShuffleNet 1x与MobileNet效果差不多,但是ShuffleNet 1x的复杂度要远小于MobileNet,差不多事MobileNet的四分之一。
4.5 ARM平台上的真实速度评估
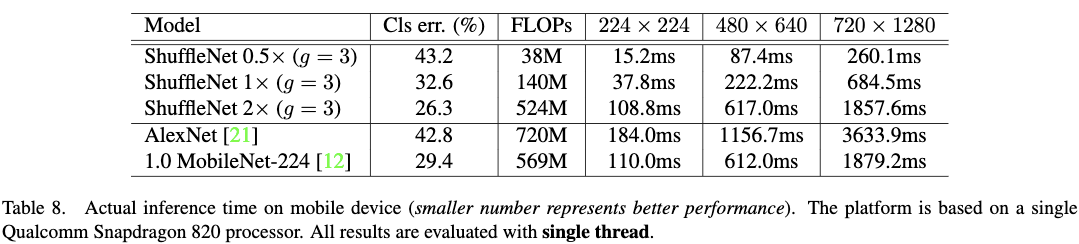
作者发现虽然g越大效果越好,但是也比较影响推断速度。而g=3是性能和速度两方面比较好的权衡。Table8给出了3中不同的分辨率下的测试结果。作者发现他们的实现方案,复杂度每降低4倍,速度可以提高2.6倍。最终与AlexNet相比,ShuffleNet 0.5x在准确率保持基本一致的情况下,可以带来13倍的加速。这个速度比同等准确率下的其它模型或者加速方法都要快。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices_CVPR2017_ZhangX et al
文章字数:1.9k
本文作者:xieweihao
发布时间:2018-01-22, 13:13:03
最后更新:2020-01-23, 10:19:34
原始链接:http://weihaoxie.com/post/876b210.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

