2017_Light-Head R-CNN:In Defense of Two-Stage Object Detector_CVPR2017_LiZ et al
一、背景及意义(动机)
在这篇论文中,作者调查了为什么两阶段的方法没法跟一阶段的方法一样快。作者发现主要原因是两阶段方法的检测部分太重了,很影响速度,即使把backbone换成轻量级的也无法提速。比如faster-rcnn使用了两个很大的全连接层去对每个区域的候选目标做进一步的筛选和定位。resnet backbone+faster-rcnn使用了整个resnet第五stage去对每个区域的候选目标做进一步的分类和定位,这些都是很耗时的;另外由于ROIpooling出来的特征也很大,所以在接入第一层全连接层的时候,运算量也会很大,这些都对速度带来很大的影响。为了解决逐区域预测带来的计算量的极大消耗,R-FCN使用了一个区域共享的全卷积神经网络去对每个ROI区域做进一步的筛选和定位,但是R-FCN使用了一个很大的位置敏感得分图,这个也很消耗内存和计算时间。为此作者提出了一个轻量级的ROI特征提取层及轻量级的检出头,构建了一个高效但是准确率很高的两阶段检测器。在使用resnet-101作为backbone,并加上提到的轻量级ROI特征提取层及轻量级检出头,并在保持时间效率的情况下,提到的方法可以超过在COCO数据集上最先进的检出方法。当将backbone替换为类xception的网络结构的时候,更是可以在COCO测试集上以每秒102帧的速度达到30.7mmAP的效果,在速度与准确率上远超YOLO和SSD.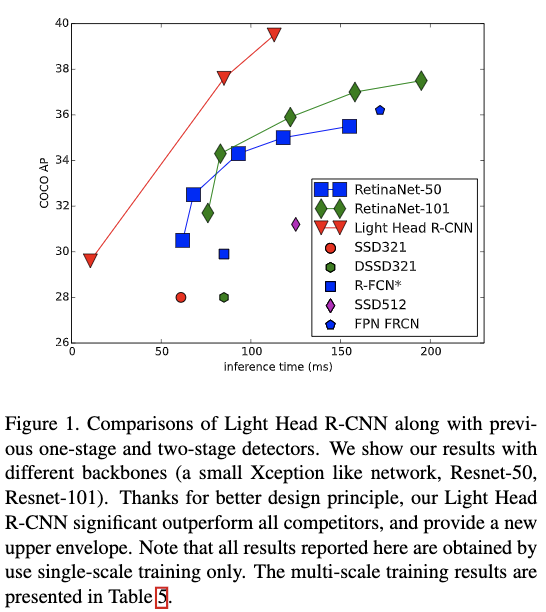
Figure 1为提到的方法在使用不同的backbone下,与最先进的目标检测方法在准确率和速度上的对比情况。
二、使用什么方法来解决问题(创新点)
- 提出了一个轻量级的ROI特征提取层及轻量级的检出头,构建了一个高效但是准确率很高的两阶段检测器。
- 高准确率版本的Light-Head R-CNN在COCO test-dev上与其他最先进的方法的对比要比最优方法高出1.4个点。
- 快速版本的Light-Head R-CNN与最先进的快速检测器做比较,在速度和准确率上都比最先进方法要好。
三、方法介绍
3.1 Light-Head R-CNN
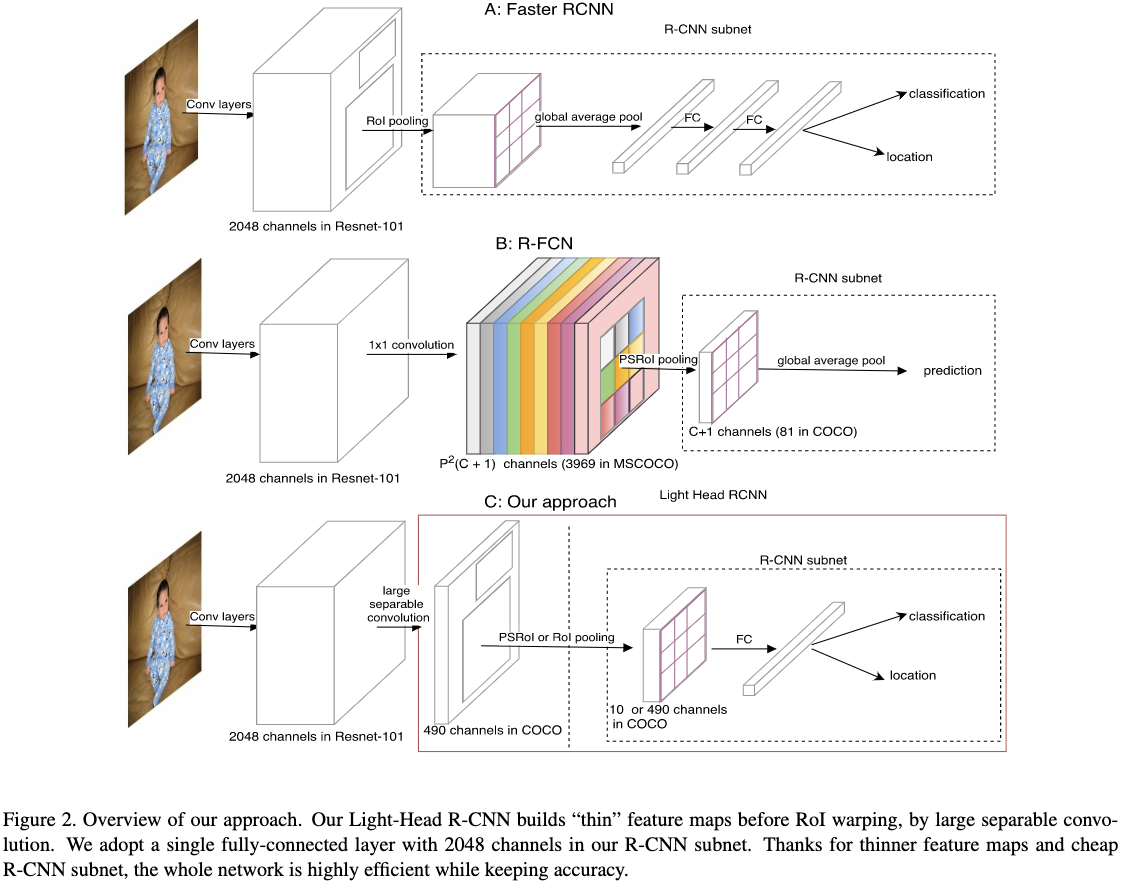
传统的目标检测器的目标检出部分包括两个部分:一个是R-CNN子网,另一个是RoI warping。只考虑准确率的话,faster rcnn更加擅长对ROI进行分类,但是为了降低计算量,通常在R-CNN子网里面会使用一个全局的平均pooling层,这样往往会造成空间信息的缺失从而影响到定位效果;而RFCN则是直接使用位置敏感Pooling层去得到ROI的分类和定位结果,这种方式没有进行逐区域的计算,性能往往比faster rcnn差。只考虑速度的话,faster rcnn对每个区域都应用了一个RCNN子网速度较慢,特别是当候选目标比较多的时候,速度更加慢;RFCN没有对每个区域使用RCNN子网,但是它需要生成一个很大的位置敏感得分图,也很耗时。faster rcnn和RFCN网络整体结构如Figure2(a)和Figure2(b)所示。考虑到这些问题,作者使用一个简单的全连接层作为R-CNN子网,并减少用于R-CNN子网的特征维度,构建了一个Light-Head的R-CNN网络。构建的Light-head RCNN网络整体结构如Figure2(C)所示。
3.1.1 Thin Feature maps for RoI warping
在将候选的特征输入到R-CNN子网之前,会使用RoI warping将候选的特征固定在一定的维度。作者在提到的网络中,使用了一个小的特征图供RoI warping提取特征。作者发现小特征图不仅可以提高准确率而且还能够节省内存和计算时间。在使用小的特征图之后,R-CNN子网可以不用使用全局平均pooling,从而可以提高性能;R-FCN也可以在接一个子网去提升R-CNN的效果。
3.1.2 Light-Head R-CNN for Object Detection
- backbone
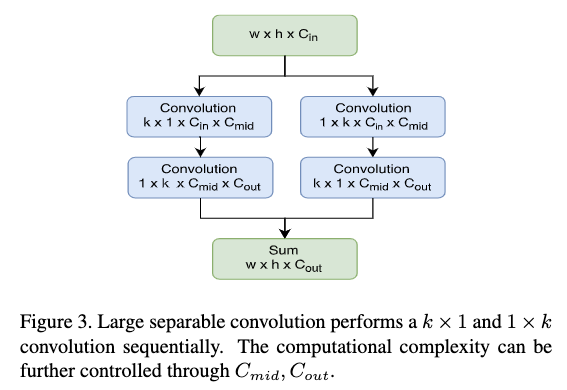
作者使用了两种backbone,”L”为高准确率版本;”S”为高速度版本。”L”backbone作者使用了ResNet101;”S”backbone作者使用了类Xception的网络结构。为了产生小的特征图,作者在$C_5$卷积层上应用了一个大kernel的分解卷积层,结构如Figure3所示。这里k为15,对于”S”,$C_{mid}=64$;对于”L”,$C_{mid}=256$。作者也将$C_{out}$减小为$10\times p\times p$,相对于RFCN的位置敏感得分图要小很多。 - R-CNN subnet
在每个ROI区域上作者使用单层全连接层(通道数为2048没有加入dropout)然后接入两个全连接层用于RoI的分类和回归,以此作为R-CNN子网。这里回归任务是类别无关的。 - RPN
作者将RPN接在$C_4$层,anchor包括了5种尺度3种宽高比,尺寸为$\{32^2,64^2,128^2,256^2,512^2\}$,宽高比为$\{1:2,1:1,2:1\}$。在使用RPN得到候选之后,作者使用IoU阈值为0.3的NMS来过滤掉冗余的目标;然后根据候选目标与grouth truth bbox的IoU来为anchor分配标签。当候选与grouth truth的IoU最大或者IoU大于0.7则被分配为正样本。当候选与grouth truth的IoU小于0.3,则被分配为负样本,其它的被忽略。
四、实验结果
作者使用具有80个类别的COCO分类任务去评估提到的方法的有效性。并使用trainval-115k作为训练集,val-5k作为验证集。
4.1 实现细节
- 使用8个Pascal TITAN XP GPU
- 使用同步的SGD
- 权重衰减系数为0.0001,动量系数为0.9
- 每个batch-size每个GPU2张图片,每张图片训练的时候选择2000个RoI候选,测试的时候选择1000个RoI候选
- 每个mini-batch将图片pad成一样大小,位置是在图片的右下角
- 前1.5M次迭代(这里的迭代是值1张图片)学习率为0.01,之后0.5M次迭代学习率为0.001
- backbone为resnet的所有实验,在stage5都使用了孔洞卷积,并使用在线困难样本挖掘(OHEM)
- backbone使用imagenet分类任务进行预训练。
- roipooling大小为7x7
- 实验的时候作者固定了backbone的第1、第2个stage。
- 采用水平翻转数据增强方式
4.2 Ablation Experiments
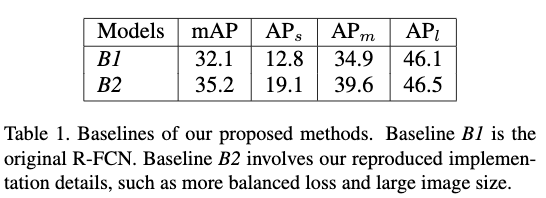
Table1给出了两个baseline,一个是原本的R-FCN,另一个则是在原本的R-FCN上对参数进行调整得到的更好的结果。调整方式包括:1)将图片的短边缩放到800像素,并设置最长边不超过1200。2)将RPN的anchor的尺度变成5,为$\{32^2,64^2,128^2,256^2,512^2\}$.3)将回归任务的损失函数的权重翻倍。4)在线困难样本挖掘的时候使用top256个样本5)训练的时候使用2000个候选,测试的时候使用1000个候选。
4.2.1 使用小feature map对性能的影响
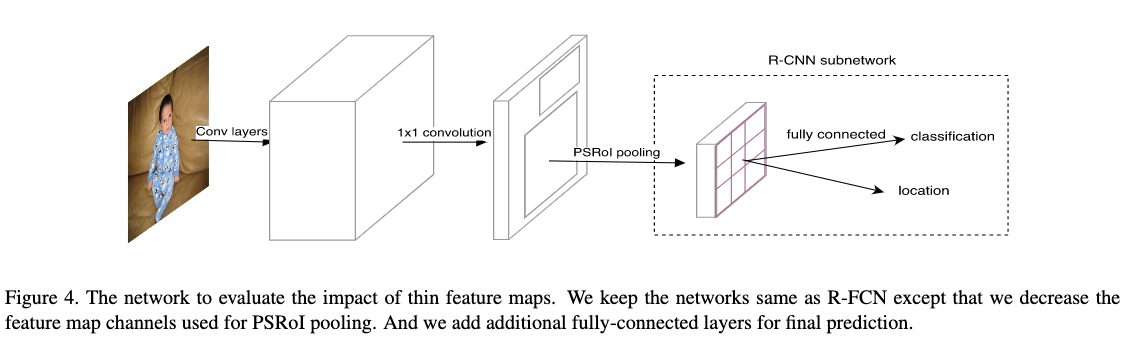
如Figure4所示,作者对原本的R-FCN做了两个调整。1)减少了原本的R-FCN的敏感得分图的通道数,从$3969(81\times 7\times 7)$减少到$490(10\times7\times7)$;2)在RSRoI pooling层之后接入两个全连接层去执行分类和回归任务。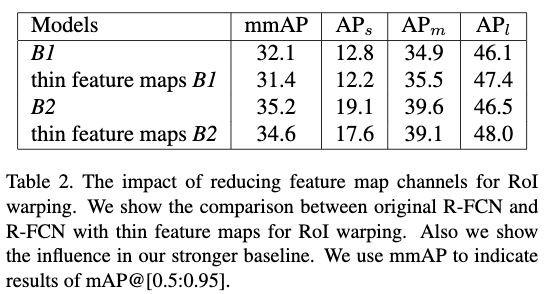
从结果可以看出,虽然通道数减少了很多,但是结果下降并不多。另外通过使用小的feature map也可以在此结构上使用FPN网络来进一步提高性能。
4.2.2 使用Large separable convolution对性能的影响
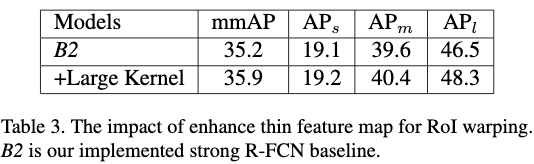
原本为了减小feature map作者使用了1x1卷积,在使用由Large separabel convolution生成的小feature map去提取RoI区域特征之后,AP要比baselines高0.7个点。
4.2.3 使用Light-Head R-CNN对性能的影响

从结果可以看出在使用Large Kernel之后使用Light-Head R-CNN对效果提升明显。
4.3 Light-Head R-CNN,高准确率下的设置

为了获得更高的准确率,作者结合了最新的目标检测方法。如Table6所示。在使用”L”backbone的基础上,作者将RoIAlign提到的差值方法应用到了PSRoI pooling上,带来了1.3个点的提升。在此基础上,作者将nms抑制的阈值从原本的0.3,变成了0.5,带来了0.6个点的提升。紧接着作者使用了多尺度的训练方式,将图片随机reshape到{600,700,800,900,1000}然后将图片的短边reshape到训练对应的尺度上,带来了1个点的提高。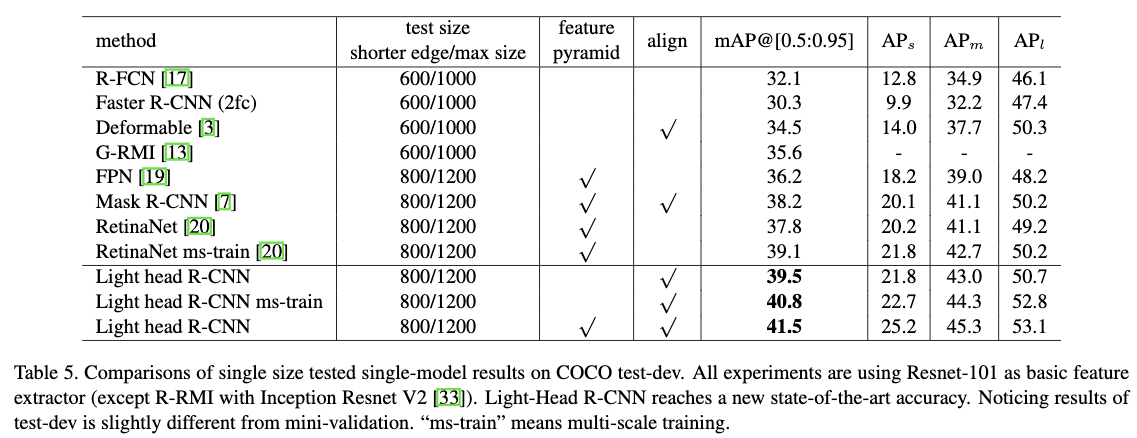
Tabel5给出了高准确率的Light-Head R-CNN在COCO test-dev上与其他最先进的方法的对比结果。从结果可以看出提到的方法要比最优方法高出2.4个点。
4.4 Light-Head R-CNN,高速度下的设置
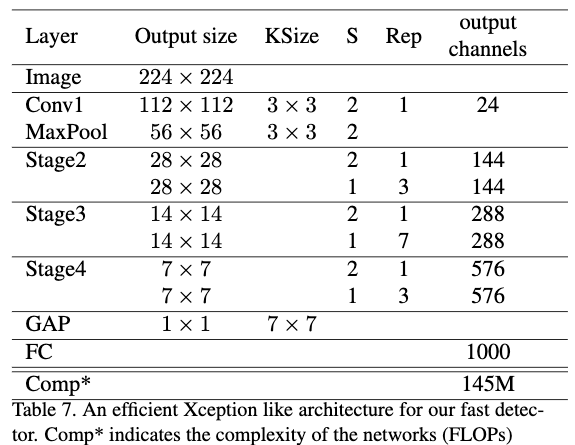
为了让推断速度更快,作者对网络及相关设置做了一些调整。包括:1)利用xception提到的逐通道卷积替换掉resnet中的卷积层,并且由于网络比较浅作者没有使用pre-activation设计。具体的网络结构如Table7所示。2)弃用孔洞卷积。3)将RPN卷积的通道数设置为256,为原来的一半。4)应用一个$kernelsize=15$,$C_{min}=64$,$C_{out}=490$的large sparable convolution。5)使用对齐的PSPooling层。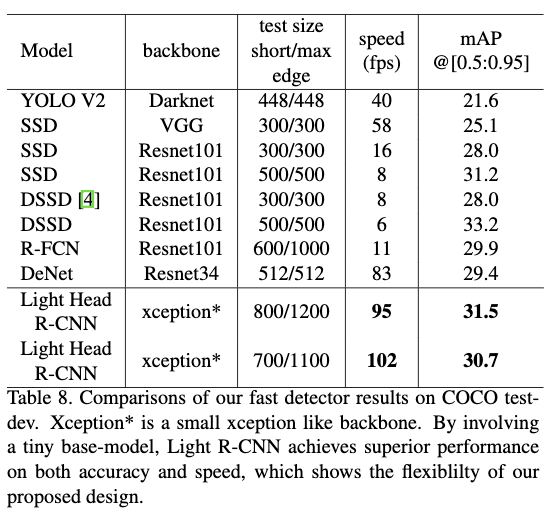
如Table8所示作者将快速版本的Light-Head R-CNN与最先进的快速检测器做比较,在速度和准确率上都比最先进方法要好。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_Light-Head R-CNN:In Defense of Two-Stage Object Detector_CVPR2017_LiZ et al
文章字数:2.5k
本文作者:xieweihao
发布时间:2018-01-20, 21:34:46
最后更新:2020-01-23, 10:20:29
原始链接:http://weihaoxie.com/post/f4b2034c.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

