2017_Focal Loss for Dense Object Detection(ICCV2017)Tsung-Yi Lin
一、背景及意义(动机)
目前准确率最高的目标检测方法主要是基于两阶段的方法,第一阶段筛选候选目标,第二阶段对候选目标做进一步筛选,包括分类及精确的定位。而一阶段的目标检测方法则是在密集的候选目标上做分类和定位。虽然一阶段的方法会更快更简单,但是准确率与两阶段的方法比还是差很远。在这篇论文中,作者探究了为啥会出现这种情况。作者发现,目标检测方法在训练的时候,前景和背景的数量极度的不平衡,造成了训练上的困难。为了应对这种困难,在两阶段的方法中,首先在第一阶段的时候通过RPN网络将大部分的背景去除掉,然后在第二阶段的时候再通过采样策略,如控制前景背景的比例为1:3或者是使用OHEM,从而大大减轻了样本的不平衡;而对于一阶段方法,候选目标很多,容易区分的样本占比更大,类似的采样策略比如bootstrapping和HEM作用没那么大。为此作者针对这种情况,对交叉熵损失函数进行改进,提出了在训练过程中能够自动关注困难样本的损失函数Focal Loss,Focal Loss其实就是可以根据样本难度自动分配权重的损失函数,越容易区分的样本权重越小,相对的困难样本权重越大。最后作者设计了一个单阶段的目标检测模型RetinaNet,并采用Focal Loss对其进行训练。该模型速度上跟一阶段模型一致,但是能达到比当前最先进的两阶段方法更高的准确率。
代码https://github.com/facebookresearch/Detectron
二、使用什么方法来解决问题(创新点)
作者针对一阶段的目标检测方法在训练过程中出现的极度的正负样本不平衡问题,对交叉熵损失函数进行改进,提出了在训练过程中能够自动关注困难样本的损失函数focal loss,focal loss其实就是可以根据样本难度自动分配权重的损失函数,越容易区分的样本权重越小,相对的困难样本权重越大。
三、方法介绍
3.1 Focal Loss
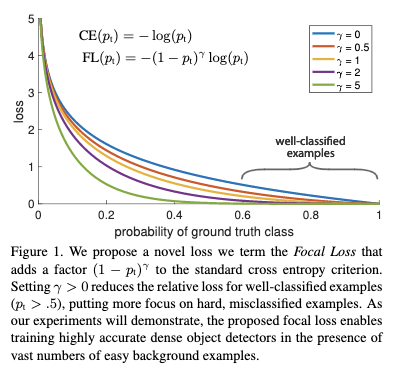
Foacl Loss是在交叉熵loss的基础上引入了根据样本困难程度对样本权重进行自动变更的机制,所以这里先从普通交叉熵loss开始逐步引入focal loss。
3.1.1 普通交叉熵loss
普通的二值交叉熵loss可以表示为: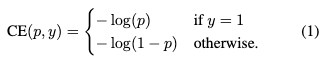
这里的类别标签为+1和-1,$p$为类别$y=+1$的概率值,为了表示方便,作者定义$p_t$为: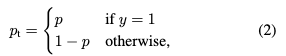
则交叉熵loss可以简单写为: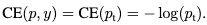
在Figure1中蓝色曲线是普通的交叉熵loss,可以看出对于容易区分的样本,产生的loss还是比较大的,如果这样的样本很多,则整体的loss会被大量这种容易区分的样本所占据。
3.1.2 加权交叉熵loss
为了处理类别不平衡的问题,通常会在交叉熵loss中引入一个权重因子,该权重因子$a$数值在0到1之间,这里类别+1分配的权重为$a$,则类别-1分配的权重为$1-a$。一般情况下在正样本偏少时$a$则相对要选择大一些。这里为了方便表示,类似$p_t$,也引入一个标记$a_t$。因此,$a-CE$ Loss可以表示为: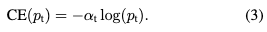
3.1.3 Focal Loss
在类别不平衡的情况下,普通的交叉熵loss会被大量容易区分的样本所占据。而加权交叉熵loss虽然可以处理类别不平衡问题,但是它没办法区分困难样本和容易区分的样本。而Focal Loss则可以根据样本的困难程度调整对应的权重。为了达到这个目的,作者在交叉熵loss上加入了一个调节因子$(1-p_t)^r,r>=0$,这里的r是可以调整的,因此Focal
Loss可以表示为: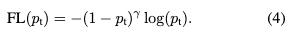
Figure1给出了不同$r$下各个概率值下的Focal Loss的变化情况,从中可以看出Focal Loss有两个性质:
1)当样本被误分类并且$p_t$较小的情况下,这个调节因子会接近1,这时候loss并没有受到影响,而当$p_t$逐渐接近1的时候,这个调制因子会接近于0,这时候容易区分的样本的重要性会逐渐降低。
2)随着$r$的增大,调节因子的影响会越来越大,会有更大范围的概率值接收一个较小的调节因子,这样容易区分的样本权重就越小,相对的困难样本的重要程度不断的提升。
在实际应用中,更多会使用如下的加权Focal Loss形式。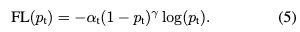
加权的Focal Loss会比不加权的情况下效果要好一些。最后作者发现在实现的时候,组合sigmoid去计算$p_t$可以在计算focal loss的时候,数值更加稳定。
3.1.4 类别不平衡情况下模型的初始化
通过将最后一层卷积层的bias设置为$-log((1-\pi)/(\pi))$,其输入到sigmoid函数后会得到$\pi$,这个$\pi$即为开始的时候稀有类的概率,通过设置$\pi$为较小的值,可以让模型在开始训练的时候更关注稀有类。这种设置对于在开始训练的时候存在大量负样本占据主导作用情况下很有帮助,可以加快模型的训练。本文作者将其设置为0.01。
3.2 RetinaNet Detector
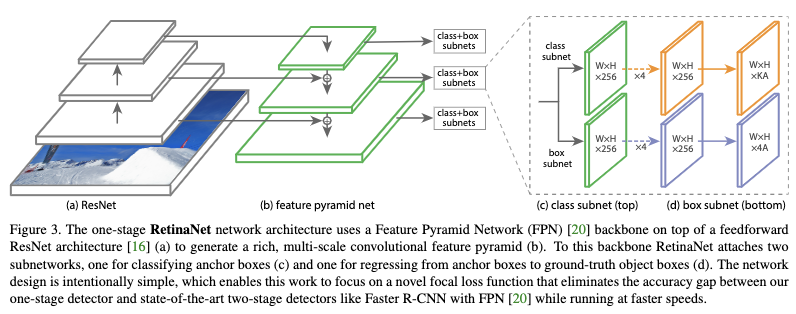
3.2.1 网络结构设置
- backbone
使用FPN作为backbone,并构建从$P_3$到$P_7$的金字塔层,这里$P_l$层金字塔的分辨率是输入的$1/P_l$倍,每个金字塔层的channel为256。这里作者采用FPN作为backbone,主要是因为只用最后一层特征效果较差。 - anchor设置
anchor大小为$32^2$到$512^2$对应$P_3$到$P_7$层金字塔,每一层金字塔层anchor的宽高比为$\{1:2,1:1,2:1 \}$,为了达到更加准确的定位,作者在每一层金字塔上将原来的anchor数增加到3个,大小设置为$\{ 2^0 ,2^{1/3}, 2^{2/3} \}$。所以在每一层金字塔层上共有A=9个anchors,所有的anchor跨过尺度范围为32到813。每个anchor被分配了一个长度为K的one-hot向量,用于目标的分类和一个4维向量用于目标的定位。当anchor与ground-truth的IOU大于0.5时,该anchor为正样本,当IOU在0到0.4之间时,该anchor为负样本,当IOU在0.4到0.5之间则被忽略。 - 分类子网
分类子网是一个FCN网络并且被所有金字塔层所共享。该FCN包括4个3x3通道数为256的卷积层,每个卷积层的激活函数都为ReLU;然后接一个3X3,通道数为KA的卷积层。K为目标类别数,A为anchor个数;最后再接一个sigmoid激活函数。 - 回归子网
回归子网与分类子网类似,只是在最后的卷积层只使用了4A个channel,并且不加sigmoid激活函数。这里作者使用的是类别无关的bbox回归器。这里分类子网和回归子网权重不共享。
3.2.2 训练和测试的参数设置
- 测试过程
整个模型由ResNet-FPN backbone,分类子网和bbox回归子网构成。推断过程只需要一个简单的前向传播过程。为了提高速度,作者只对每个金字塔层预测的置信度大于0.05的前1000个bbox进行解码;然后将所有的候选合并并进行阈值为0.5的nms抑制,得到最终的结果。 - focal loss
在训练分类子网的时候,作者使用了focal loss。作者发现在实际应用中$r=2$可以取得比较好的结果,并且当$r=[0.5,5]$区间时,效果比较稳定。在训练过程中focal loss被应用到图片中的所有约100k个anchors中,这与启发式采样和OHEM不同,它们只是选择了一部分数据用于训练。最终的loss为所有anchor的focal loss之和,除以被分配为正样本的anchor数。这里作者没有除以所有的anchor,主要是因为很多的负样本都很容易区分,focal loss几乎可以忽略。作者发现将r设置为2,将a 设置为0.25表现效果是比较好的。 - Initialization
作者先使用ImageNet1k数据对ResNet-50-FPN和ResNet-101-FPN进行预训练;然后对于新加入的卷积层,除了分类子网的最后一层,都使用0均值标准差为0.01的高斯分布进行初始化,并将bias设置为0;对于分类子网最后的卷积层作者将bias设置为$b=-log((1-\pi)/\pi)$,则在接入一个sigmoid操作后,输出的概率就为$\pi$,这里的$\pi$表示的是在开始训练的时候,每个anchor都有pi的置信度被标记为前景,这里作者将pi设置为0.01,这样对于大量的负样本带来的影响就比较小,loss会更加关注正样本。这个设置方式有助于前几个epoch训练的稳定。 - Optimization
在8GPU上使用同步SGD进行训练。每个GPU2张图片,每个minibatch16张图片。所有的模型训练90k个迭代,起始学习率为0.01,在第60k次迭代变为0.001,第80k次迭代变为0.0001。数据增强只使用水平翻转。权重衰减系数为0.0001,动量为0.9.训练的loss为focal loss和smooth L1 loss。训练时间再10到35个小时之间。
四、实验结果
使用COCOtrainval-135k数据集进行训练,minival-5k数据集进行验证。测试指标主要是COCO-AP。
4.1 验证不同设置的影响
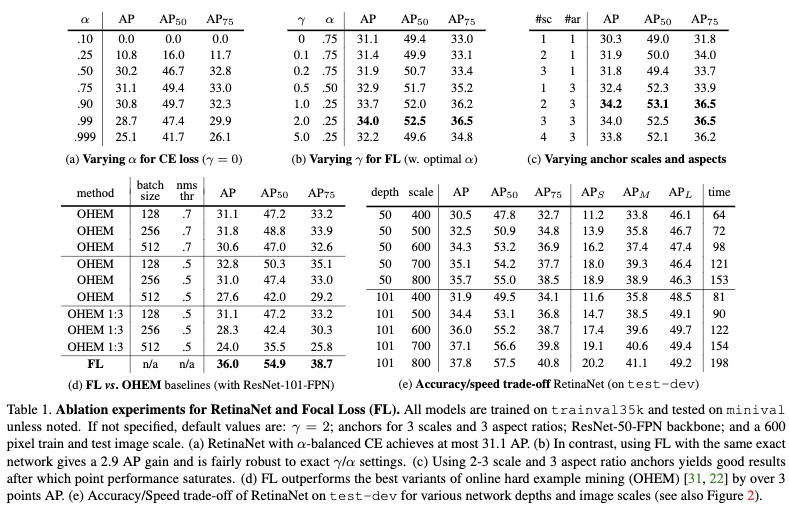
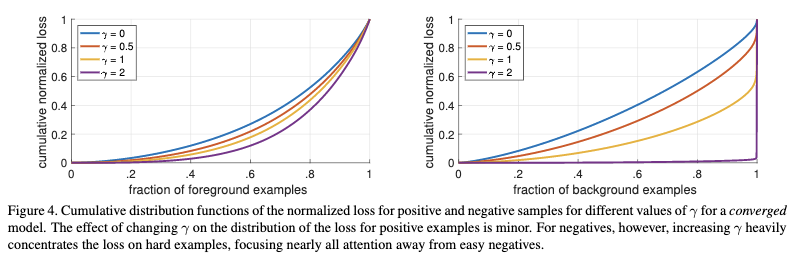
从上图可以看出随着r越来越大,训练的时候会越来越关注困难负样本,而对于正样本的影响则是比较小的。
4.2 与当前最先进方法的对比
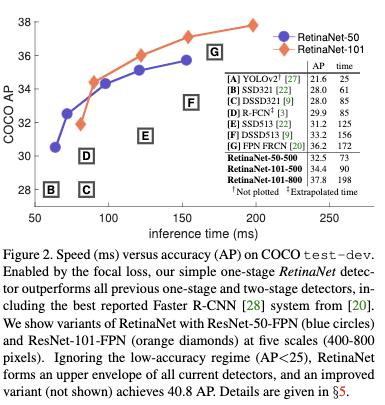
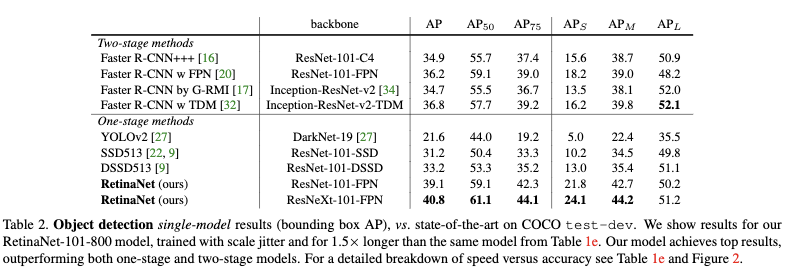
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_Focal Loss for Dense Object Detection(ICCV2017)Tsung-Yi Lin
文章字数:2.6k
本文作者:xieweihao
发布时间:2018-01-17, 15:36:06
最后更新:2020-01-23, 10:17:33
原始链接:http://weihaoxie.com/post/eb34d552.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

