2016_Deep Residual Learning for Image Recognition_CVPR2016_HeK et al
一、背景及意义(动机)
网络深度是深度神经网络性能提高的一个重要因素,但是在模型深度达到一定程度时,会出现梯度消失或者梯度爆炸的问题而很难训练。BN的出现极大程度解决了梯度消失或者爆炸带来的问题,使得训练更深层的网络更加容易。但是却带来了另一个问题,退化问题。随着网络深度的增加,模型在训练过程中准确率的增加会慢慢饱和,随后准确率反而开始下降。这个问题的出现表明并不是所有网络结构都很容易优化。为了解决深度神经网络网络层数太深而难以训练的问题,作者提出了残差学习框架。使用该框架可以解决由于网络层数太深而难以训练的问题。在此基础上作者提出resnet网络结构,该网络结构可以构建深度比vgg深很多倍,但是模型复杂度比vgg小的网络结构,并且效果要比vgg更好。使用提到的网络结构作者在ILSVRC分类任务以及COCO目标检测和分割任务中都取得了第一名。
二、使用什么方法来解决问题(创新点)
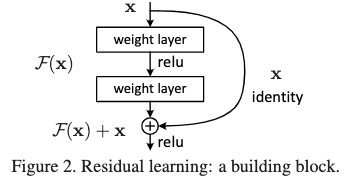
作者通过引入深度残差学习框架来解决退化问题。跟原本让堆叠的多层网络去学习一个潜在的映射不同,作者强制让他们去学习一个残差映射。假设原本学习的潜在映射是H,那现在堆叠的多层网络则是学习映射F,这里F=H-x。原本的映射则为H=F+x。作者认为这种方式要比原本的更加容易优化,因为在极端的情况下,当模型饱和的时候,输入端可以通过shortcut connection直接跳过非线性层。残差模块的构建也很简单,只需要通过shortcut connnection将输入端恒等映射到输出并加到原本堆叠的多层网络的输出上。
这种做法的动机:为什么使用残差学习可以解决退化问题呢?作者给出了一个解释:模型通过多个非线性层来学习恒等映射是比较困难的。但是通过残差学习的形式,让多层非线性层去学习接近于0的输出从而让整体输出接近恒等映射则要容易很多。当网络达到一定复杂度的时候,很多时候会需要让多余的表达能力去拟合一个恒等映射,通过残差表示可以让模型更容易学习恒等映射,从而可以消除退化问题。
最后作者通过实验证明了该方法十分有效。不仅很容易优化深层网络,而且也不会出现退化问题,反而能够很有效的利用深度的增加带来的增益。
三、实现细节
1.网络结构
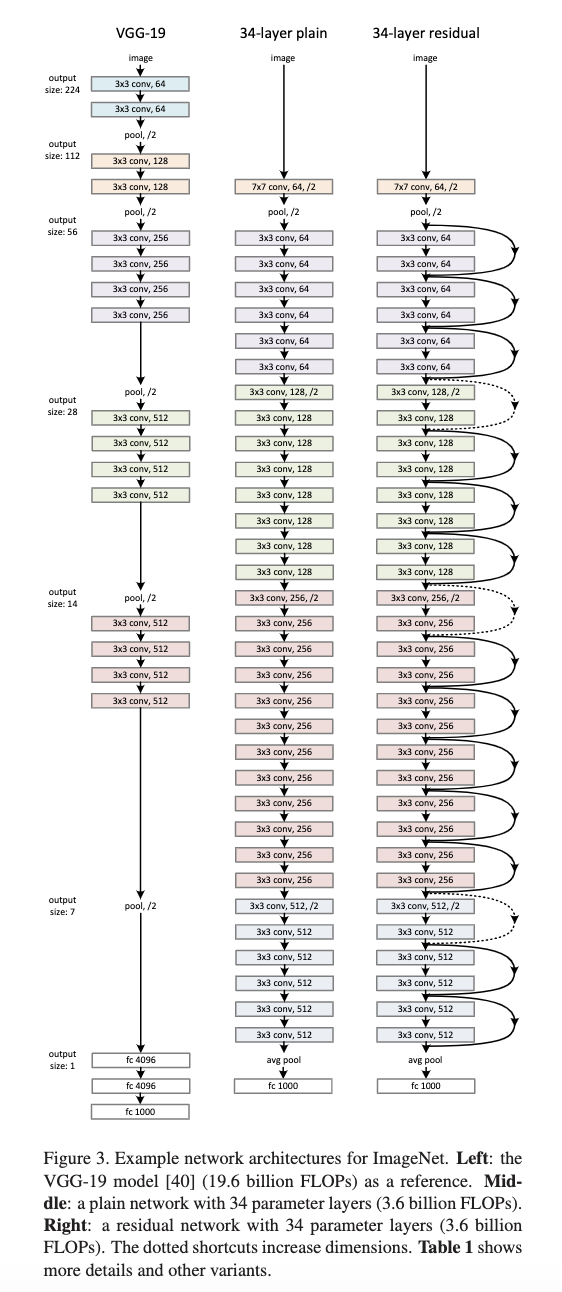
这里作者按照vgg网络的构建思路(a.相同的feature map大小,具有相同数量的filter b.当feature map大小减半的时候,对应的filter数量增加一倍。)构建了一个新网络,并在此基础上对其加入shortcuts连接,变成对应的resnet版本。构建的网络相较于vgg网络,具有更低的复杂度,约为VGG的18%。构建的resnet网络,当输入和输出维度相同的时候(如上图实线),使用恒等映射进行连接。当维度增加的时候(如上图虚线)作者考虑了两种操作。A.使用zero padding进行补齐 B.使用1X1的卷积增加维度,这两种操作stride都为2。
2.实现细节
2.1 ImageNet分类任务
训练时参数设置:
- 预处理:减去均值图片
- 数据增强:1)将图片的短边随机缩放到[246,480]之间进行尺度增强。2)从缩放后的图片中随机crop224 * 224大小的图片 3)对图片进行随机水平翻转。4)进行颜色增强。
- 在每个卷积和激活函数中间加入BN层。
- 正则化:权重衰减系数为0.0001;动量参数为0.9;没使用dropout。
- 优化方法:SGD;batch-size大小为256;起始学习率为0.1;学习率衰减方式为当误差无法下降的时候将学习率除以10;迭代次数为60* 10^4以上。
- 参数的初始化方式参考:K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
测试时参数设置:
- 采用多种尺度的全卷积形式,然后将得分取平均。尺度包括将短边resize为{224,256,384,480,640}
四、实验
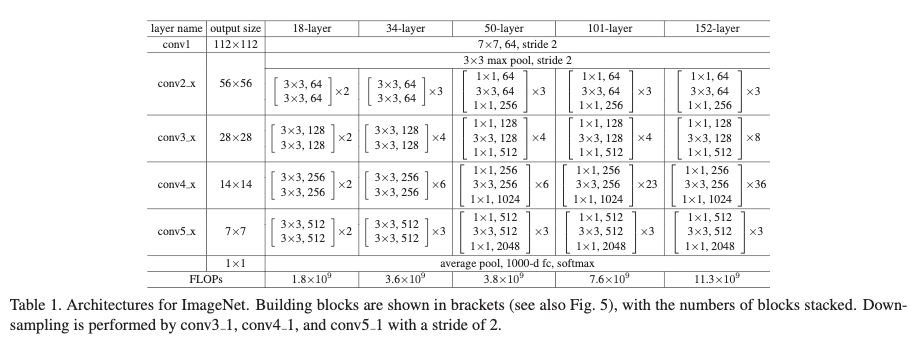
4.1 Imagenet 分类任务(试验用的模型结构如上图)
4.1.1 Plain Networks vs Residual Networks
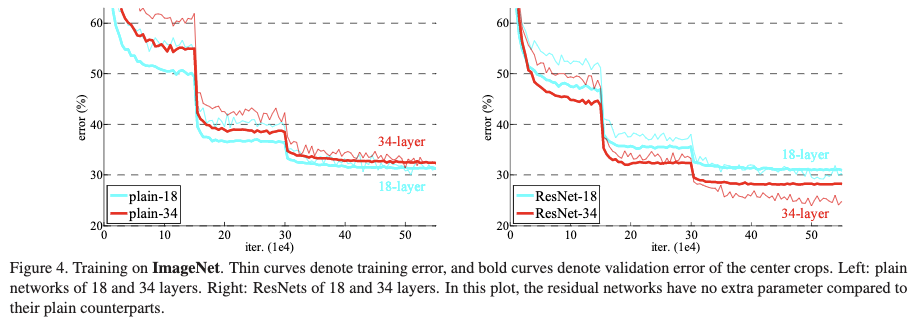
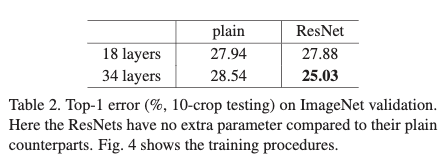
从Figure4和Table2的结果可得出以下几个结论:
- 没加入残差结构的时候,普通的18层网络反而比普通的34层网络具有更大的训练误差和测试误差,出现了退化问题。当加入残差结构的时候,退化问题消失了,并且模型可以从增加的深度获取增益。
- 从Figure4中可以看到,34层的resnet相较于普通的网络训练误差低很多,可以看出resnet可以有效用于训练很深的网络。
- 虽然18层的resnet和普通版本虽然具有相似的准确率,但是相较于普通版本resnet版本拟合得更快。
4.1.2 Identity vs Projection Shortcuts
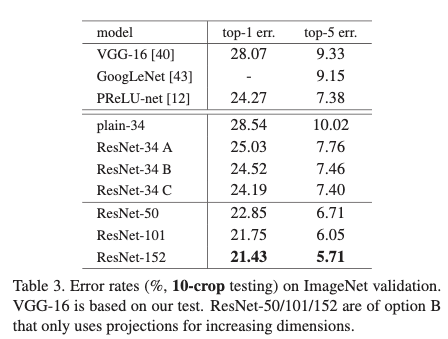
作者调查了3种形式的shortcut结构:A)zero-padding shortcuts用于增加维度,其它时候使用Identity shortcuts B)projection shortcuts用于增加维度,其它时候使用Identity shortcuts C)所有都是用projection shortcuts。发现projection shortcuts并不是处理退化问题的关键,shortcuts才是关键。
4.1.3 Bottlenet Architectures
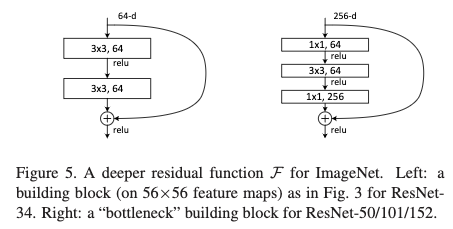
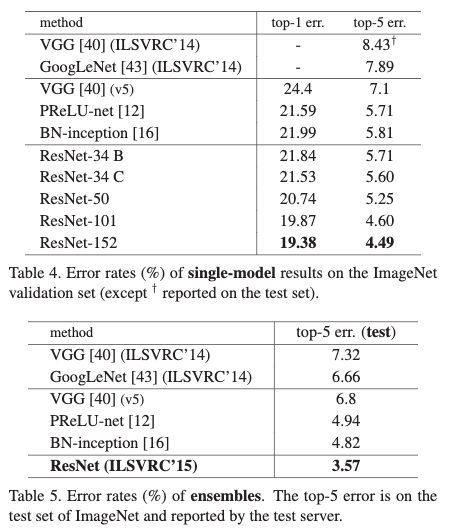
为了在控制的训练时间内,探索残差模块对训练更深网络的效用,作者使用了bottlenet结构,将每个残差模块中的2层卷积替换为3层卷积。先使用1x1卷积进行降维,之后再使用1X1卷积扩张维度。这样使得复杂度与原本2层结构相似。构建的网络结构如table1中50层resnet,101层resnet和152层resnet。从table3和table4中可以看出更深的网络效果更好,而且不会出现退化问题。table4为提到的方法与最先进的几个方法的对比,从结果可以看出resnet效果具有很大的提升。
4.2 CIFAR-10 分类任务
作者在CIFAR-10数据集上也得出了类似的结论另外作者也对响应值情况和是否能够训练更深的网络进行了探索: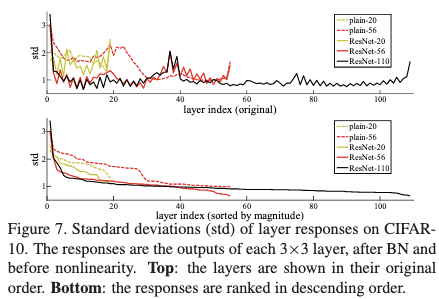
- 作者也对卷积层的响应情况进行分析(Figure7),并得出以下结论:
1)相较于普通网络,resnet网络的响应值更加小。
2)层数更多的resnet,会产生更多小响应值。这两个结论与原本的动机想符合。 - 作者也尝试将网络层数增加到1000层,发现网络依然能够正常训练,说明残差结构对于训练深层网络是很有用的。
4.3 PASCAL 和 MSCOCO目标检测任务。
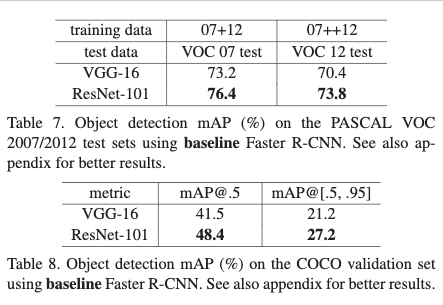
在目标检测任务中,作者简单的将vgg网络替换为res101就获得了很大的增益,说明该方法对于其他识别任务也同样有效。并以此网络结构作者赢得了ILSVRC和COCO2015各项比赛的第一,其中包括Imagenet 检测,Imagenet定位,COCO检测和COCO分割任务。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2016_Deep Residual Learning for Image Recognition_CVPR2016_HeK et al
文章字数:2k
本文作者:xieweihao
发布时间:2017-01-14, 17:17:21
最后更新:2020-01-23, 10:20:58
原始链接:http://weihaoxie.com/post/92de5aab.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

