2019_Scale-Aware Trident Networks for Object Detection_ICCV2019(Oral)_LiY et al
一、背景及意义(动机)
尺度变化对于目标检测来说,是个很关键的挑战。为了应对该挑战,有两个主要的方向,一个是利用图像金字塔,另一个则是使用网络内的特征金字塔来近似图像金字塔。多尺度的训练和测试以及SNIP都是利用了图像金字塔带来了整体检出性能的提高,特别是SNIP提高更是显著,但是这种方式大大增加了推断的时间,如fig1(a)所示。SSD和FPN则是利用了网络中的多层特征来近似图像金字塔,虽然取得了一定的效果,但是通过不同的特征层来提取目标的不同尺度信息并无法替代图像金字塔,因为输入两个不同分辨率的图像,其在网络中对应于同个图像分辨率下的同个目标区域的特征是不同的,这里特征金字塔中的每层特征都有一系列不同的参数,使得不同层的特征不具有同等的表达能力,这样也有过拟合的风险,如fig1(b)所示。不管图像金字塔还是特征金字塔,都有相同的动机,就是不同尺度的目标应该具有不同的感受野。为了利用图像金字塔和特征金字塔的优点,摈弃它们的缺点,作者在这篇论文中,首先通过一个探究性的实验,探究在目标检测任务中感受野对于不同尺度的目标有什么影响。然后基于对探究性实验的分析得出的结论,提出一个新颖的三分支网络(TridentNet),如fig1(c)所示,该网络可以使用同等的表达能力为同个目标,生成不同尺度的特征图。TridentNet是一个并行的多分支结构,每个分支共享相同的参数,但是具有不同的感受野,不同感受野的实现主要是靠调整孔洞卷积的dilated rate参数。为了让具有不同感受野的分支能够适应不同的尺度,作者提出了一个尺度适应的训练框架。该训练框架主要是在对每个分支进行训练的时候,只使用适应该分支感受野大小的目标来训练该分支。另外由于TridentNet在推断的时候需要跑3次网络,比较影响推断速度,为此在推断的时候作者提出了TridentNet的快速近似版本。TridentNet的近似版只需利用中间分支跑一次网络,相较于原版快速版本只牺牲了很小的性能,但是相较于普通的目标检测器,快速版本可以在没有额外参数和计算代价的情况下极大提高检出性能,也使得该方法更加能够应用到实际中。最后作者在使用ResNet-101作为backbone的情况下,将COCO目标检测的mAP提高到48.4,这是目前单模型能达到的最高性能。
代码:https://git.io/fj5vR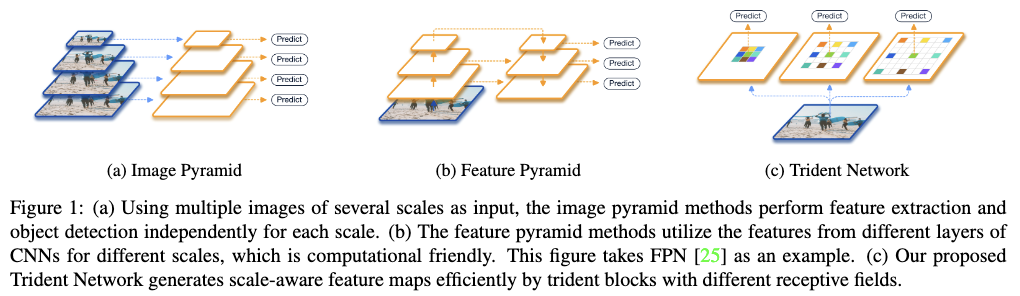
二、使用什么方法来解决问题(创新点)
2.1 本文的创新点及贡献
- 通过探究不同感受野对不同的尺度的目标的影响,揭露了为获得更好的性能,大目标应该使用更大的感受野,而小目标则应该使用相对小的感受野。
- 提出TridentNet去解决目标检测任务中目标尺度变化范围较大的问题。该方法通过孔洞卷积来实现不同尺度大小的目标,使用不同的感受野进行识别;并使用尺度适应的方式选择合适大小的目标来训练具有不同感受野的分支。最后通过该方法可以为同个目标生成具有同等表达能力的多尺度特征,但是只需要输入单分辨率的图像。
- 为了加快推断速度,作者提出了TridentNet的近似版本,该版本受益于权重共享的trident-block设计,只需要利用中间分支跑一次网络,在没有增加额外参数和计算代价的情况下,性能稍微比原版差一点,但是比起最先进的目标检测方法性能要提高很多。
- 作者在COCO数据集上验证了该方法的有效性,在使用ResNet-101作为backbone的情况下,mAP提高到48.4,这是目前单模型下能达到的最高性能。
三、方法介绍
3.1 探究不同感受野对不同尺度的目标检出性能的影响
对于检出器来说,有很多设计因素会影响到最终的检出性能,包括网络深度,下采样率和感受野。网络深度和降采样率对结果的影响已经在很多工作中被调查过了,一般来说深度越深效果越好,下采样率越小效果越好。但是目前还没有对感受野的影响进行调查,为此作者首先设计了一个探究性实验,探究了感受野对目标检测的性能的影响。
为了让检出器在同等复杂度的情况下,具有不同的感受野,作者使用空洞卷积替代了backbone网络中某些卷积层,利用dialation rate来控制网络的感受野。
作者以ResNet-C4作为backbone,测试了具有不同感受野的Faster RCNN在COCO检出任务上的性能。评价指标使用COCO-style的mmAP,并给出了所有目标,小目标,中等目标和大目标的mmAP。作者测试了两个backbone,ResNet-50和ResNet-101,并通过改变第4个stage中的residual blocks中的$3\times3$卷积层的dilation rate,来得到同等复杂度不同感受野的Faster R-CNN,dilation rate的变化范围从1到3。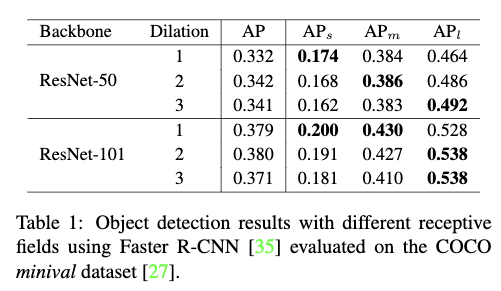
Table1总结了两个不同backbone在不同的dilation rate下的性能。从Table1中可以看出随着感受野的增大,小目标的性能在不断下降,而大目标的性能则在不断提高。从中也可以总结出两点:1)网络的感受野会影响不同尺度的目标的检出性能,即适合的感受野能提高特定尺度范围内的目标的检出性能。2)尽管ResNet-101理论上具有足够大的感受野去覆盖COCO数据集中所有大尺度的目标,大目标的检出性能也可以通过进一步增大感受野来得到提升。这也暗示了有效的感受野要小于理论的感受野。通过增大dilation rate可以提高有效感受野使大目标的性能得到提高,但是同时也会影响到小目标的性能。所以不同尺度的目标要平衡好不同的感受野,才能达到更好的效果。
3.2 TridentNet
如Fig2所示,TridentNet主要包括了权重共享的Trident blocks以及适应不同分支的感受野的尺度适应训练框架。另外为了加快推断速度,作者提出TridentNet的快速版本。下面分别就这3部分做介绍。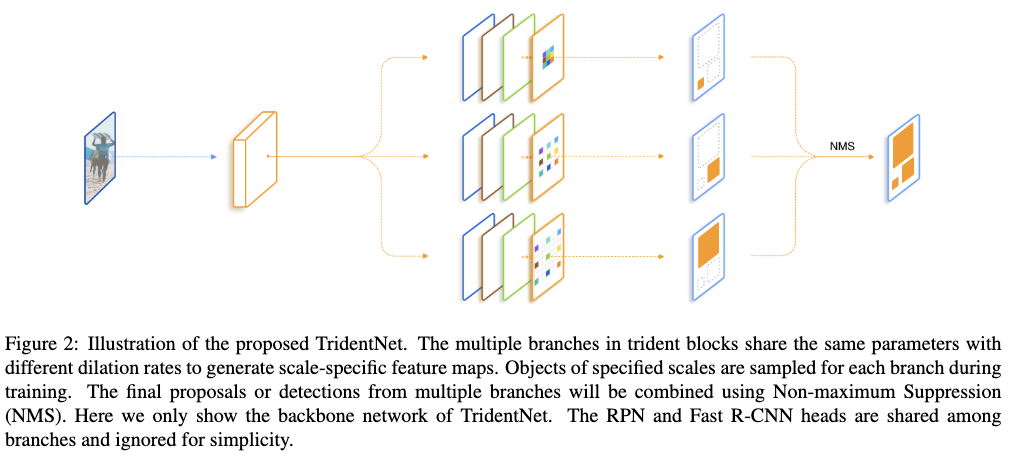
3.2.1 权重共享的Trident blocks
作者提出的TridentNet其实就是利用提到的Trident block去替代检测器中某些卷积blocks。Trident block包括多个并行分支,每个分支与原本的卷积blocks共享相同的结构,除了采用不同的dilation rate。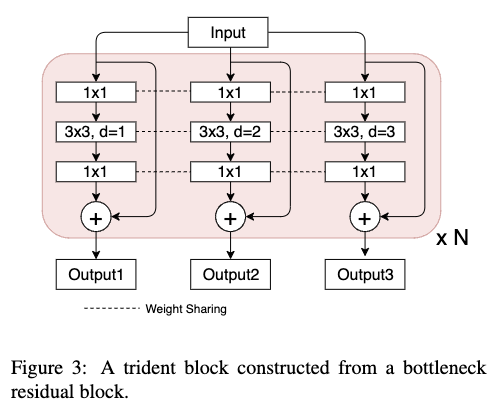
以ResNet为例,每个bottlenet形式的residual block包括3个卷积层,kernal size分别为$1\times1,3\times3,1\times1$。如Fig3所示,与其对应的trident block则是具有同样的卷积层数,同样的kernal size,但是每个分支的$3\times3$卷积层具有不同的dilation rates。通过堆叠多个trident block可以很容易去控制不同分支的感受野。一般来说,会将trident block放置在最后一个stage,因为最后一个stage的stride比较大,这样各个分支的感受野差距比较明显。
由于每个分支具有相同的结构,所以可以让多个分支的权重进行共享,这样也避免了过拟合。在本文中,每个分支除了dilation rate不同之外,其它的都相同。权重共享带来了3个好处:1)相较于原本的检测器,不需要增加额外的参数;2)同个目标的不同尺度输入到网络之后得到的特征的表达能力是相同的;3)形态,姿势等变换参数可以从所有的目标中学习到,而不会减少训练目标的数量,从而不会影响到性能。
3.2.2 适应不同分支的感受野的训练框架
从Table1中可以看出,感受野与目标尺度的不匹配会导致性能的下降。即使在多个分支的情况下,如果使用所有的目标来训练,那每个分支都存在尺度与感受野不匹配的目标,这将会影响每个分支的性能,从而影响到最终性能。为此作者在训练具有不同感受野的分支的时候,使用了尺度与其适应的目标来训练。
与SNIP类似,作者为每个分支定义了一个有效的尺度范围,在训练的时候只选择尺度在有效范围内的grouth truth和proposals。具体的对于在原图上(没resize之前)宽度为w,高度为h的ROIs,其有效的尺度范围如下: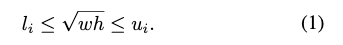
这个训练框架可以同时应用到RPN和R-CNN。在训练RPN的时候,作者只选择每个分支对应的有效的grouth truth boxes为每个分支的anchor分配标签。在训练R-CNN的时候,作者将每个分支无效的proposals移除掉,不用于训练。
3.2.3 用于推断的快速版本
TridentNet的推断过程是,首先为每个分支生成检出结果,然后将各个分支中没有落在其有效范围内的目标全部过滤掉,最后将所有有效的目标组合在一起,利用NMS或者soft-NMS过滤掉冗余的目标,得到最后的结果。
由于每个分支需要跑一次测试结果,这种方式会比较影响推断的速度,为此作者剔除了TridentNet的快速版本。TridentNet的快速版只需要对一个主要分支进行预测,这里作者使用了中间的分支,因为中间分支的有效范围同时覆盖了大目标和小目标。TridentNet的快速版本可以在牺牲很小的检出性能的情况下,达到与普通检出器同等的推断速度。这可能是由于权重共享策略,通过权重共享和多分支的训练,就等同于在网络内部应用多尺度增强。
四、实验结果及重要结论
作者在COCO数据集上进行实验,并按照通用的数据集使用方式,将80k训练集图片和验证集中的35k图片合并起来作为训练集,并利用验证集中的剩余5k图片作为一个小的测试集(minival)。在跟最先进方法比较的时候,作者也给出了它们在20k张测试集图片上的效果(test-dev)。
4.1 实现细节
- 作者利用mxnet重新实现了Faster R-CNN检测器。
- 检测器的backbone是在ImageNet1000上进行预训练的,在使用预训练的模型初始化的时候,作者固定了第一个residual阶段,并冻结所有的BN参数。
- 输入的图片被rescale到短边为800。
- 采用随机翻转进行数据增强。
- 模型在8个GPU上进行训练,一个batchsize16张图片。
- 默认情况下,模型训练12个epoch。
- 起始学习率为0.02,然后在8个和第10个epoch,学习率分别乘以0.1。
- 这里的2$\times$和3$\times$分别表示将训练的epoch总数翻倍和翻三倍,对应的学习率机制也对应发生改变。
- RPN网络接在ResNet的Conv4上,R-CNN网络接在ResNet的Conv5上。
- 默认使用3个分支,三个分支的dilation rates被设置为1,2,3。
- 对于每个分支,在NMS之前取top12000个候选目标,在NMS之后取top500个候选目标,并采集128个ROIs训练R-CNN。
- 当采用适应不同分支感受野的尺度适应框架来训练的时候,三个分支选择的目标尺度分别为[0,90],[30,60],[90,无穷大]。
- 评估方法使用平均精度AP,也给出IOU为0.5的AP和IOU为0.75的AP,作者也给出了COCO-style的$AP_s$,$AP_m$和$AP_l$,分别表示小目标(像素小于$32\times32$)、中等目标(像素大于$32\times32$小于$96\times96$)和大目标(像素大于$96\times96$)的平均精度。
4.2 探究提到方法中的不同结构对性能的影响
4.2.1 探究TridentNet各个组成部分对性能的影响
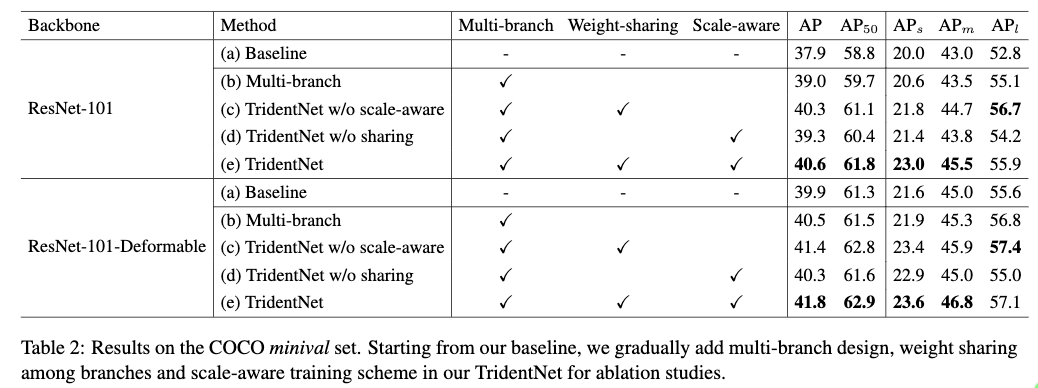
Table2给出了在Baseline的基础上,逐步增加各个组成部分后对整体检出性能的影响。这里的Baseline分别是以ResNet-101和ResNet-101-Deformable为backbone的faster R-CNN。在此基础上作者逐步应用多分支体系结构,权重共享设计和适应不同感受野的尺度适应训练框架来看看各个部分对整体检出性能的影响。
Table2(b)为直接使用3个具有不同的感受野不进行权重共享的分支来进行目标检测。从Table2中可以看到,使用多个不同感受野的分支,对两个不同backbone的faster R-CNN检出器的性能,都带来了提升。对于大目标的提升更是明显。这个也证明了使用不同的感受野对不同尺度目标检出性能的提高很关键。
Table2(d)为在多分支的基础上,使用尺度适应框架来训练的结果。从结果来看,整体的性能并没有得到提升,虽然它提高了小目标的检出性能,但是却降低了大目标的检出性能。作者认为虽然各个分支使用了合适的尺度进行训练,避免了使用过大过小的目标尺度的情况,但是整体训练样本却减少了,这样有可能带来过拟合。
Table2(c)为在多分支的基础上,进行权重共享,但是每个分支使用所有尺度的目标来训练。从Table2(c)中可以看出权重共享在两个不同的backbone下都得到了提高。通过权重共享的方式可以减少模型的参数避免过拟合,从而是检出器的性能得到提高。
Table2(e)为在权重共享的基础上,使用尺度适应的训练框架。由于权重共享设置,使得网络训练的时候仍然使用所有的样本来训练,减少了过拟合,从而是最终的结果得到提高。但是这里其实提高并不明显。
从结果也可以看出,提到的Trident block与deformable convolution是互补的,都带来了性能的提高。
4.2.3 探究分支数对性能的影响
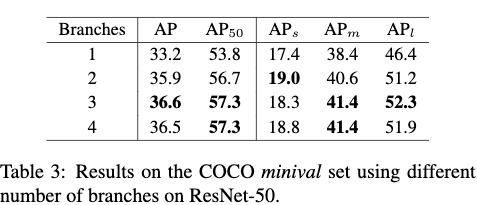
Table3给出了使用1个到4个分支的情况下,TridentNet的性能,这里并没有应用尺度适应框架,避免干扰试验的客观性。从Table3可以看出多分支比起单分支效果要提高不少,但是当分支数超过3个之后,性能开始饱和,为此作者只选择3个分支,也因此把该方法命名为TridentNet。
4.2.4 探究在网络中哪个stage放置Trident blocks最好
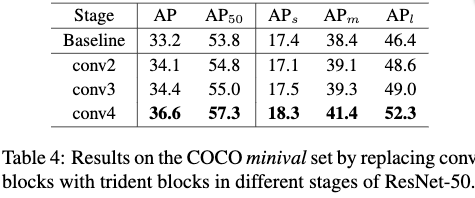
Table4给出了将Trident blocks放置在conv2,conv3,conv4 stage上的效果,对应的stride分别为4、8和16。从Table4可以看出,相较于放置在Conv4 stage,放置在Conv2,Conv3 stage上时,性能只比baseline提高一点点。这是因为conv2、conv3 stage对应的stride不够大,使得3个分支的感受野差异较小。
4.2.5 探究放置多少Trident blocks最好
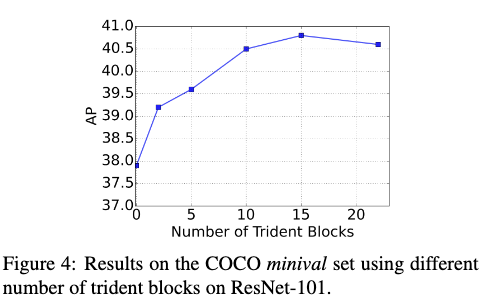
由于在Conv4 stage有很多个residual block,那应该放置多少个trident block合适呢。Fig4给出了将Conv4 stage中不同数量的residual block替换为trident block后的效果。从Fig4可以看出,当Trident block的数量超过10,TridentNet的性能就比较稳定了,也不会出现性能下降的情况。这也说明了在各个分支的感受野差异足够大的情况下,TridentNet中tridnet block的数量具有很强的鲁棒性。
4.2.6 探究每个分支的性能
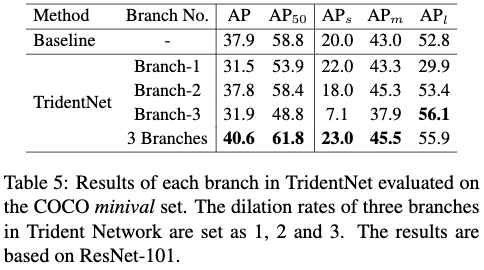
Table5给出了TridentNet中不同分支的性能及多个分支组合的性能,这里的TridentNet作者也使用了尺度训练框架。从Table5可以看出,具有最小感受野且利用小尺度目标来训练的branch-1对小尺度目标的检出效果最好;branch-2则是对中尺度的目标效果最好;branch-3对大尺度的目标效果最好。最后三分支的组合方法,从多个分支中继承了它们的优点,取得了最好的效果。
4.3 快速版本对性能的影响
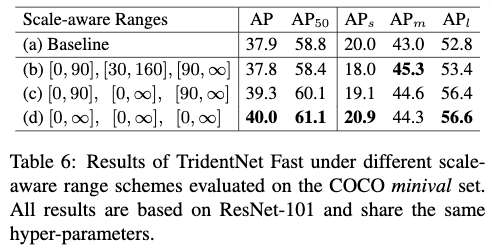
为了减少TridentNet的推断时间,作者提出了TridentNet的快速版本,快速版本只使用了TridentNet的一个主要分支来进行推断,因此可以大大节省推断时间。如Table5所示,branch-2效果是最好的,很自然地成为主分支的候选。branch-2由于同时包含了其他两个分支的结果,可以得到比其他两个分支更优的效果。Table6为使用不同尺度来训练三个分支的情况下,TridentNet的快速版本的效果。从Table6中可以看出,随着中间分支适应的尺度范围的增大,整体的AP也不断的提高,从Table6(c)可以看出当中间分支适应所有尺度范围的情况下,比起baseline AP要高出1.4个点。在将3个分支适应的尺度全部扩大到支持所有尺度的情况下,AP进一步提高到40.0,这相较于普通版本AP只减低了0.6。作者认为这主要得益于权重共享策略,这种多分支的尺度无关的训练框架就类似在网络内执行了尺度增强策略。
4.4 与最先进方法的比较
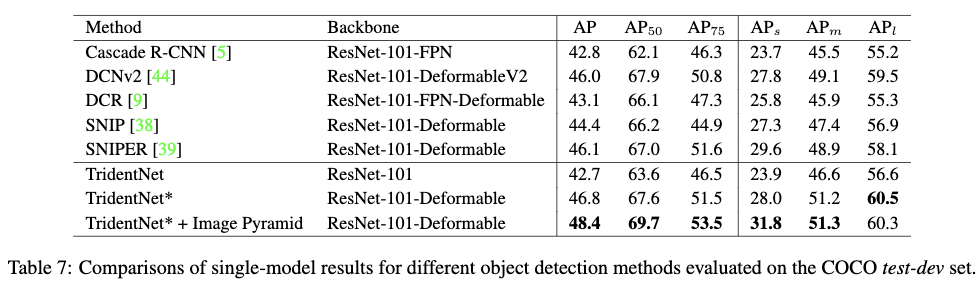
Table7给出了最先进的目标检测方法及TridentNet的不同设置在COCO test-dev数据集下的测试结果。从Table7中可以看出,TridentNet应用到以ResNet-101为backbone的faster R-CNN检测器上并在2$\times$epoch数的情况下AP可以达到42.7。为了与SNIP和SNIPER进行公平的比较,在使用跟它们一致的多尺度训练,soft-NMS,Deformable卷积,large-batch BN和3$\times$的epochs数量的情况下,AP可以达到46.8,如Table7中的$TridentNet^·$,这个指标已经超过了SNIP和SNIPER,这里还没有使用图像金字塔。在使用图像金字塔进行测试的情况下,可以将$TridentNet^*$的性能进一步提高到48.4。这是目前为止以resnet-101为backbone的情况下达到的最优的性能。在使用快速版本+图像金字塔进行测试的时候,$TridentNet^·$的AP可以达到47.6。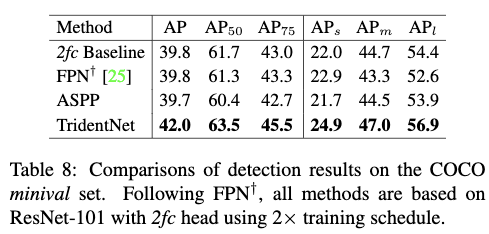
Table8给出了在R-CNN直接采用2个fc层来进行精细的分类和回归而不是采用conv5之后的网络层来进行精细的分类和回归的情况下,TridentNet和FPN,ASPP的对比情况。从Table8中可以看出,TridentNet在各个尺度上都要由于其他方法。在使用快速版本的情况下,可以AP可以达到41.0,比起baseline要高出1.2个点,这也进一步说明了该方法的有效性。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2019_Scale-Aware Trident Networks for Object Detection_ICCV2019(Oral)_LiY et al
文章字数:5.1k
本文作者:xieweihao
发布时间:2020-01-10, 17:42:38
最后更新:2020-02-25, 22:30:21
原始链接:http://weihaoxie.com/post/879cef5f.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

