2018_ShuffleNet V2:Practical Guidelines for Efficient CNN Architecture Design_CVPR2018_MaN et al
一、背景及意义(动机)
之前网络结构设计的时候采用的度量模型复杂度的方式是浮点运算数。这种方式不够直接,因为影响模型运算的因素除了浮点运算数还有其他方面。这里影响速度的因素除了浮点运算数之外,主要还有内存获取的代价(MAC)(某些操作的MAC会很大,比如组卷积),以及模型的可并行程度;另外运行平台也会对模型的运行速度带来影响,因为不同平台会对不同操作做优化。为此作者直接在指定平台上度量模型运算速度。为了设计出高效的网络结构,作者通过一系列的控制实验,推导出4个高效网络设计的指导原则,并依据这些指导原则,设计了一个新的、适用于移动设备的高效网络结构,并将其命名为shuffleNet v2。最后作者通过实验验证了该网络结构在同时考虑速度和准确度的情况下能达到当前最先进水平。在模型复杂度为40M浮点数的情况下,ShuffleNet V2要比ShuffleNet V1性能提高3.2%,要比MobileNet V2性能提高3.7%。
二、使用什么方法来解决问题(创新点)
- 提出了设计高效网络的4个指导原则。
- a 输入和输出的channel相等的情况下可以让MAC最小
- b 要小心增加分组卷积的分组个数带来的速度减缓
- c 要减少设计单元中分支的数量
- d 要尽可能少的使用逐元素操作
- 根据提出的指导原则,设计了高效的网络结构,ShuffleNet v2.
三、方法介绍
3.1 高效网络的设计原则
作者在2个不同的平台上对2个当前最流行的高效网络结构的运行速度进行分析,并推导出4个设计高效网络的指导原则。
- 作者使用的GPU平台为单个GTX1080Ti,并使用CUDNN7.0加速库,并且把CUDNN的底层函数激活让它能够对不同的卷积操作,选择最快的算法;使用的ARM平台为Qualcomm Snapdragon810,并使用一个基于Neon的高度优化的库,且只用单个线程。其他设置包括:输入的图片大小为224X224,每个网络随机初始化,并评估100次取平均作为真是的运算速度。
- 作者使用的网络结构为ShuffleNet V1和MobileNet V2。
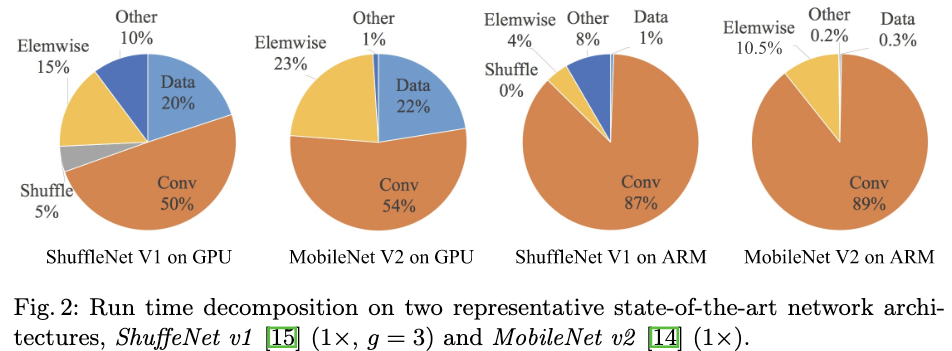
- 作者发现模型在不同平台上的运行速度主要可以分解为4个部分,浮点运算数、数据IO、逐点操作数和数据的shuffle。
- 推导出的四个设计高效网络的指导原则
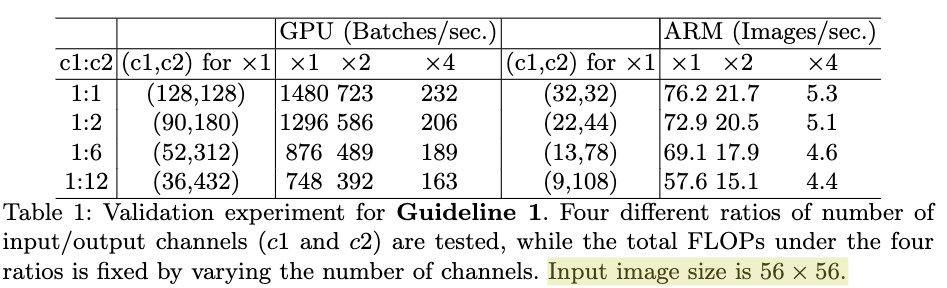 G1. 输入和输出的channel数相等的情况下可以让MAC最小。为了验证该结论,作者构建了具有有10个构建块,每个构建块包括两个卷积层,通道数分别为c1和c2的卷积网络。Table1给出了,在浮点运算数基本相同的情况下,c1和c2在不同比例下的速度。从Table1可以看出,当c1和c2比例为1:1时,速度是最快的。
G1. 输入和输出的channel数相等的情况下可以让MAC最小。为了验证该结论,作者构建了具有有10个构建块,每个构建块包括两个卷积层,通道数分别为c1和c2的卷积网络。Table1给出了,在浮点运算数基本相同的情况下,c1和c2在不同比例下的速度。从Table1可以看出,当c1和c2比例为1:1时,速度是最快的。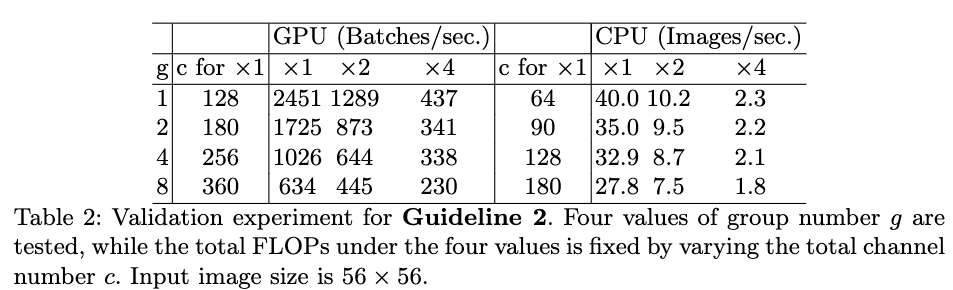 G2. 过多的分组卷积会增加MAC。为了验证该结论,作者构建了一个具有10个逐点分组卷积层的网络。Table2给出了,在浮点运算数相等的情况下,不同的分组个数下网络的运算速度。从Table2可以看出,随着分组个数的增加,运算速度在不断下降。
G2. 过多的分组卷积会增加MAC。为了验证该结论,作者构建了一个具有10个逐点分组卷积层的网络。Table2给出了,在浮点运算数相等的情况下,不同的分组个数下网络的运算速度。从Table2可以看出,随着分组个数的增加,运算速度在不断下降。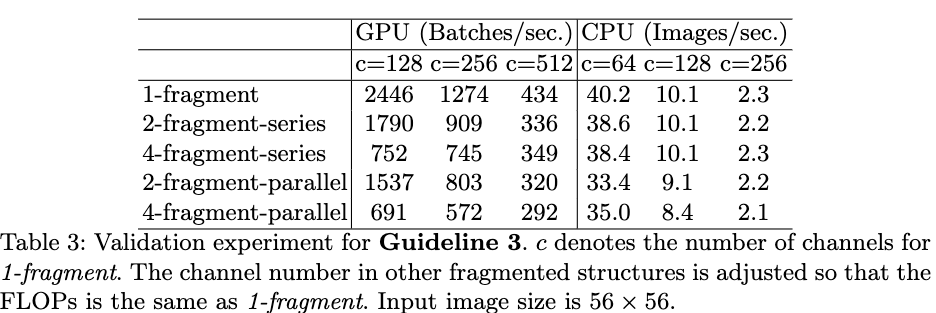 G3. block中的碎片化层度(网络层数量)会影响并行度。为了验证该结论,作者构建了多个具有不同卷积层数及不同组合方式的构建块,并堆叠同个构建块构建10层的网络结构。Table3给出了在浮点运算数相同的情况下,不同构建块的运算速度。从Table3可以看出,随着碎片化程度的增加,网络的运行速度越来越慢,但在CPU上的运行速度的减缓较为缓慢。
G3. block中的碎片化层度(网络层数量)会影响并行度。为了验证该结论,作者构建了多个具有不同卷积层数及不同组合方式的构建块,并堆叠同个构建块构建10层的网络结构。Table3给出了在浮点运算数相同的情况下,不同构建块的运算速度。从Table3可以看出,随着碎片化程度的增加,网络的运行速度越来越慢,但在CPU上的运行速度的减缓较为缓慢。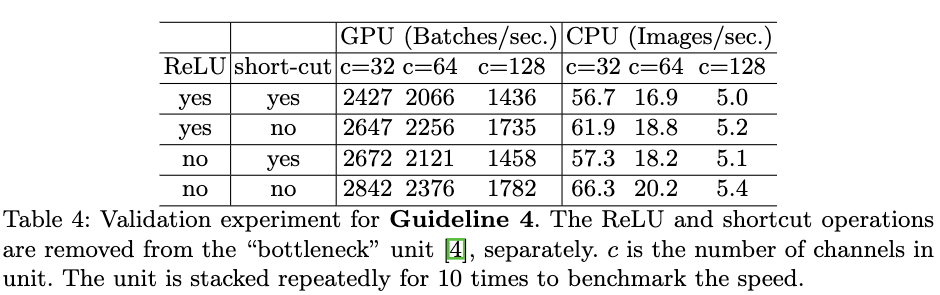 G4. 要尽可能少的使用逐元素操作。为了验证逐元素操作对模型运行速度的影响,作者对比了resnet的bottlenet形式以及移除掉shortcut和ReLU操作的模型运行速度。从Table4可以看出,在移除掉shortcut和ReLU操作后,不管是在GPU还是在CPU,模型的运行速度可以提高约20%。
G4. 要尽可能少的使用逐元素操作。为了验证逐元素操作对模型运行速度的影响,作者对比了resnet的bottlenet形式以及移除掉shortcut和ReLU操作的模型运行速度。从Table4可以看出,在移除掉shortcut和ReLU操作后,不管是在GPU还是在CPU,模型的运行速度可以提高约20%。
3.2 ShuffleNet V2
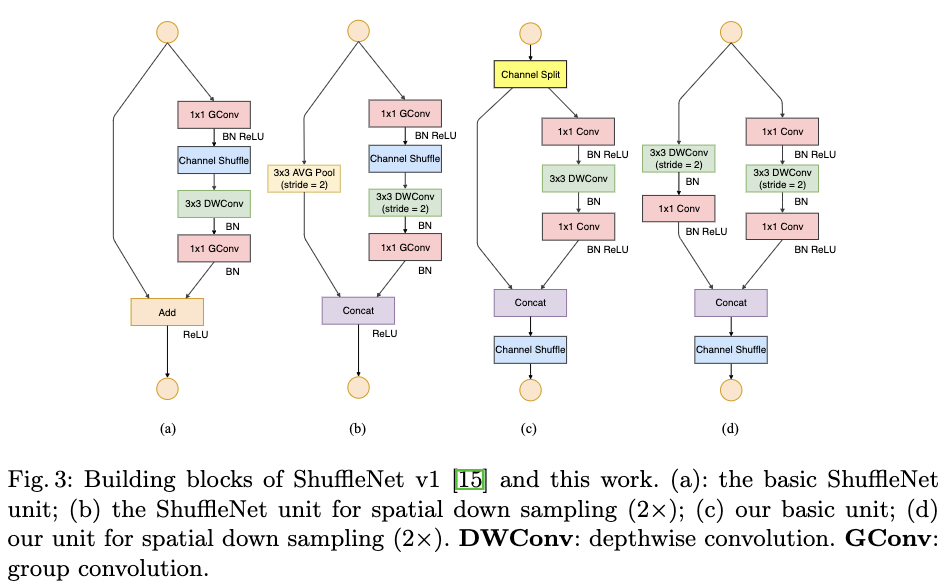
目前提出的高效网络结构,都或多或少违背了上面的几个原则。如ShuffleNet V1严重依赖分组卷积,这与G2相违背,并且其类似bottlenet的构建块也违背了G1;MobileNet V2逆bottlenet形式也违背了G1,并且在小的feature map上使用逐深度卷积和ReLu也违背了G4;自动生成的结构则被严重碎片化,违背了G3。为此作者在ShuffleNet V1的基础上,对网络结构中违背提到的4个指导原则的部分结构进行调整,即关键在于保持较多通道数的情况下,更多使用密集卷积层而不是分组稀疏卷积层。为了达到该目的作者引入了一个新的操作叫做通道划分。如Figure3(a)(b)为ShuffleNet V1的两个构建块,Figure3(C)(d)为作者在ShuffleNet V1的基础上,提出的新的构建块。
在Figure3(c)中,作者首先利用通道划分(这里作者将通道划分成数量相等的两部分),将输入通道划分成两部分一部分不做任何操作,一部分则利用3层网络对其进行处理,这样可以减少碎片化程度,这个设计遵循了G3。使用的3层网络的输入和输出通道数也是一样的,这个设计遵循了G1。3层网络中1x1的卷积层不再是分组卷积了,这个设计遵循了G2。在卷积操作之后,两个分支被拼接在一起,使得输入和输出的通道数保持一致,这也遵循了G1。由于这里其实是分成了2个组,在拼接之后作者使用了channel shuffle来使各组信息相关联。这里三个连续的逐元素操作“Concat”,“Channel Shuffle”,“Channel Split”被合并成一个逐元素操作,这也遵循了G4.FIgure3(d)为feature map大小减小1倍而feature map的通道数量增加一倍的版本。这里通道划分被移除了,因此通道数量比原来增加了一倍。Table5为提到的网络结构,ShuffleNet V2。其中不同的输出通道数,给出了不同复杂度的网络。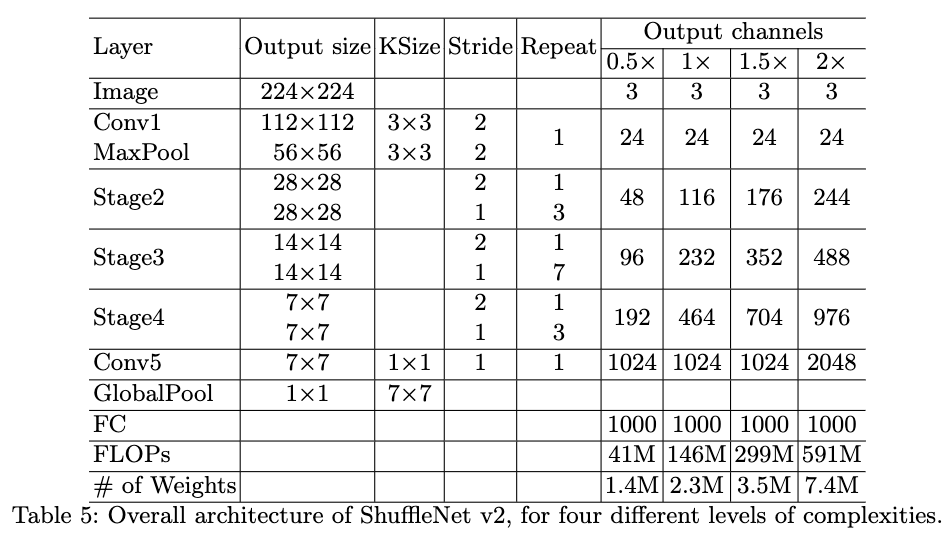
四、实验结果
作者在IamgeNet2012分类数据集上,验证了提到的网络结构的有效性。并对比了4种不同的模型复杂度下,不同网络结构的性能。超参的设置与ShuffleNet V1一致。
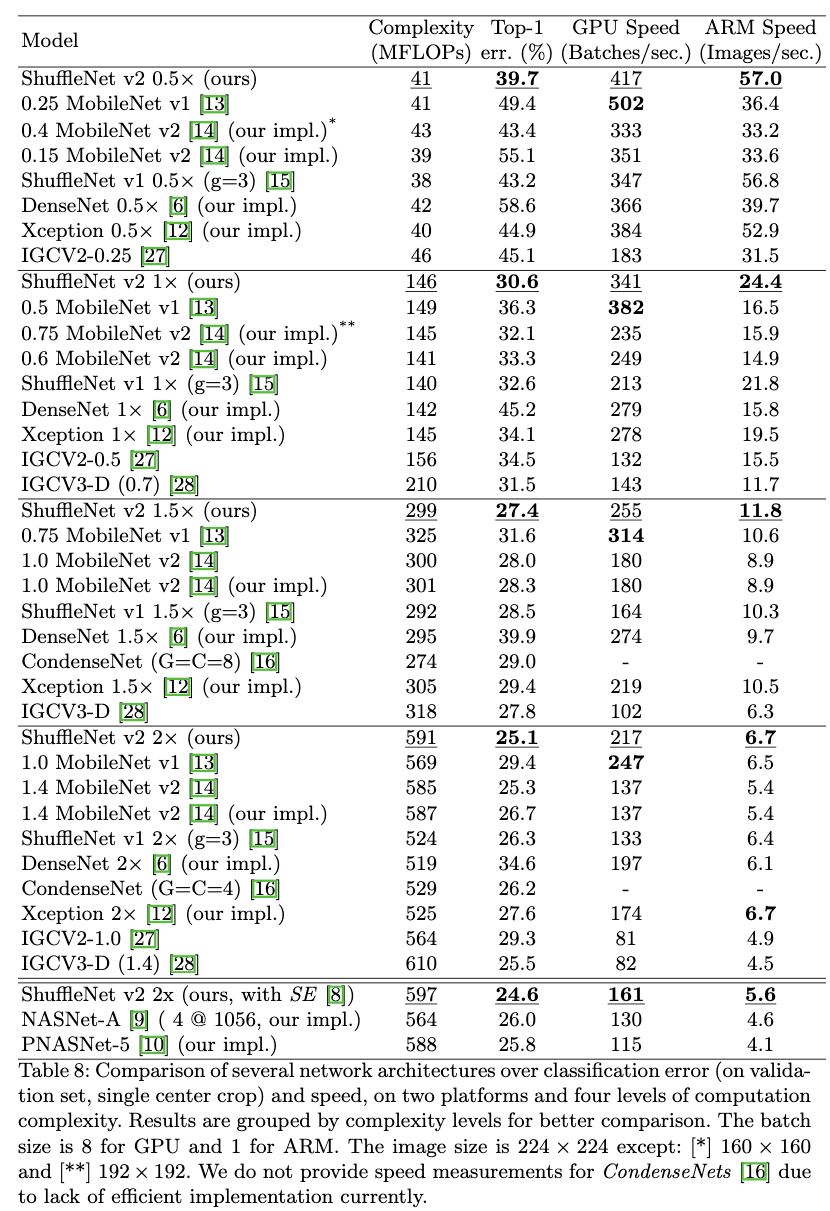
- Table8给出了在模型复杂度为40,140,300和500+ MFLOPs下各个模型的运行速度和准确率。从Table8中可以看出在相同复杂度下,ShuffleNet V2要比其他网络结构准确率要提高很多。作者注意到在复杂度为40MFLOPs,输入大小为224x224的情况下,MobileNet V2的效果很差,这可能是因为通道数太少了,但是ShuffleNet V2则由于使用更多的通道数而不会出现这种情况。在Table8中作者也对比了其他最先进的网络结构如CondenseNet,IGCV2,IGCV3,在不同的复杂度下,提到的网络结构准确率都要比它们高。
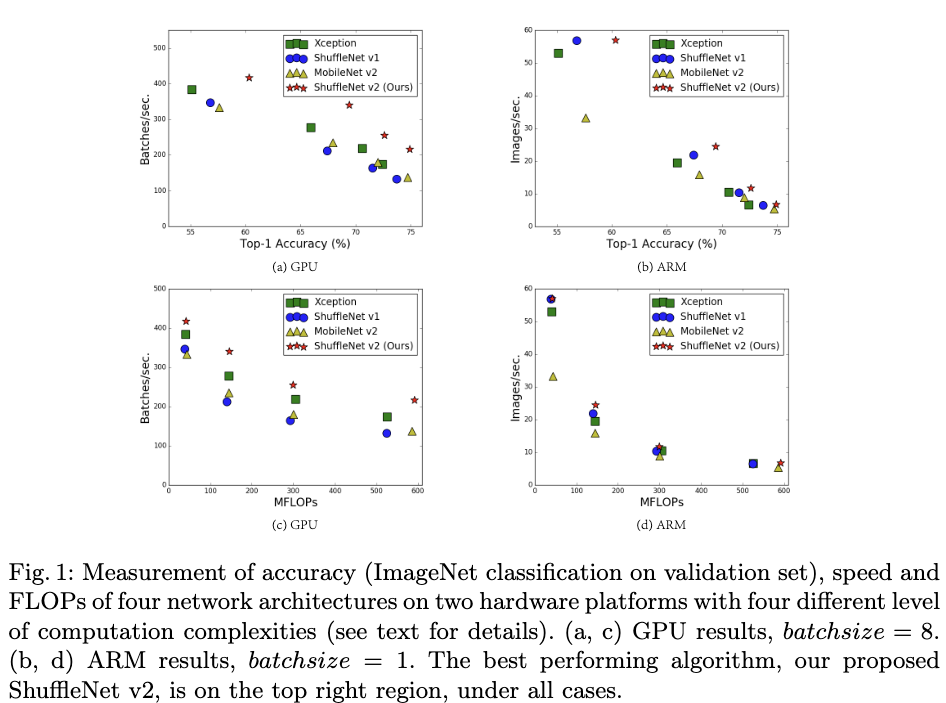
- Figure1给出了在相同模型复杂度或者准确率下,不同模型的运行速度。从Figure1(c)(d)可以看出,在相同模型复杂度下,ShuffleNet V2在运行速度上优势也很明显。 从Figure1(a)(b)中可以看出,如果同时考虑准确率和速度,ShuffleNet V2是最优的。

- Table6对比了大模型情况下,ShuffleNet V2与其他先进的网络结构。从Table6可以看出在大模型的情况下,ShuffleNet V2也要比ShuffleNet V1和resnet50更好,并且模型复杂度要比resnet50少40%。ShuffleNet能够在模型复杂度远小于SENet的情况下,准确率超过SENet。
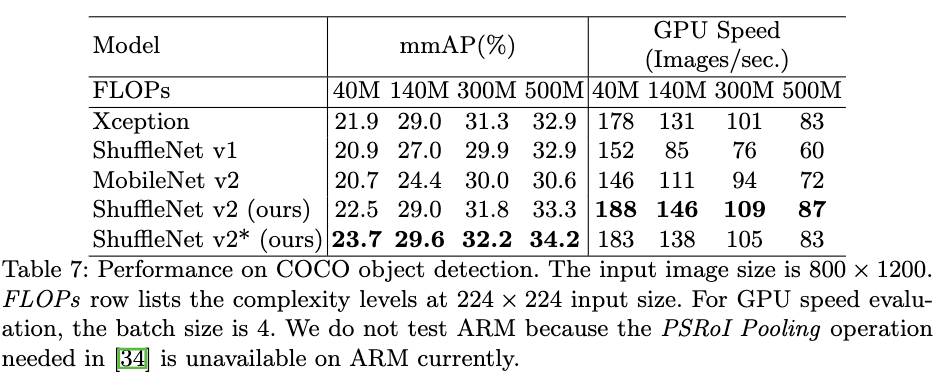
- Table7对比了在目标检测任务下,相同复杂度不同网络结构的性能。这里使用的目标检测方法是light-head RCNN,并将backbone网络替换为本论文提到的网络。从Table7可以看出,ShuffleNet V2在目标检测任务上也要由于其它网络结构,作者发现增加感受野能够提高目标检测的效果,为此作者在原本的构建块的第一个1x1卷积层之前加入了一个3x3的逐深度卷积,构建了ShuffleNet V2*网络结构,进一步提高了目标检测的效果。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2018_ShuffleNet V2:Practical Guidelines for Efficient CNN Architecture Design_CVPR2018_MaN et al
文章字数:2.3k
本文作者:xieweihao
发布时间:2019-02-01, 17:29:30
最后更新:2020-02-03, 17:38:15
原始链接:http://weihaoxie.com/post/97be11b5.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

