2017_Aggregated Residual Transformations for Deep Neural Networks_CVPR2017_XieS et al
一、背景及意义(动机)
深度学习的发展,使得计算机视觉从最开始的设计人工特征,发展到现在主要是设计网络结构。但是网络结构的超参很复杂,并不容易设计。当前比较成功的设计思想有两种方式,一种是类似于vgg-net和ResNet那样堆叠相同的构建块;另一种方式是类似Inception模型那样小心的设计网络拓扑结构,让网络在具有较强的表示能力的情况下,尽可能的较少模型的复杂度。虽然Inception模型在减少复杂度的情况下,能保持较高的性能,但是在设计网络结构的时候需要费很多心思,并且设计出来的网络结构可能会过于适应当前任务,导致对于其他任务表现不佳。在这篇文章中,作者采用VGG和ResNet的设计思想即堆叠基本的构建块,但是采用Inception的设计策略即采用多个不同的分支结构的形式,提出一个简单的网络结构。提出的模块,在执行一系列变换之后,将变换结果进行整合,即split-transformation-aggregate的方式。变换的方式可以多种多样,但这里作者采用了相同的变换方式,使得该思想具有很大的扩展性。作者将提到的网络结构命名为ResNetXt。该方法可以在维持一定复杂度的情况下,提高算法精度。作者通过实验证明,cardinality(变换的基数)是一个跟深度,和宽度同等重要的能提高算法性能的维度。甚至比增加宽度或者深度来得更加有效。该方法在ILSVRC2016分类任务上获得第二名。
代码https://github.com/facebookresearch/ResNeXt
二、使用什么方法来解决问题(创新点)
2.1 创新点
- 引入一个新的维度cardinality,并提出了一个新的网络结构。
- 通过实验证明了该维度与深度和宽度同等重要,甚至对于性能的提高更加明显。
2.2 重要结论:
- cardinality(变换的基数)是一个跟深度,和宽度同等重要的一个能提高算法性能的一个维度。甚至比增加宽度或者深度来得更加有效。
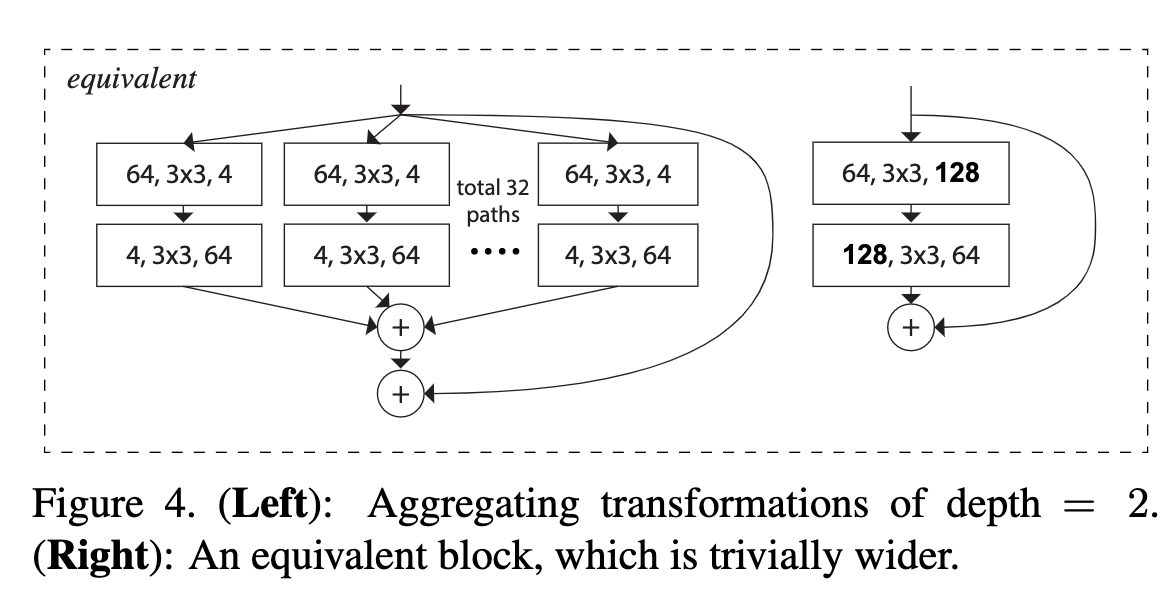
- 只要在转换深度大于等于3的时候,这种变换才有意义。
- 在Mask R-CNN中也使用了ResNeXt,并在实例分割和目标检测上达到了最先进的结果。
三、方法介绍
3.1 模块构建规则及构建的模块
- 模块构建规则
作者提出的网络结构主要采用与VGG/ResNets类似的高度模块化网络设计方式。由一系列residual模块构成。这些模块都具有相同的拓扑结构,并按照以下两种规则来构建:
1).feature map大小相同的block共享相同的超参(相同的宽度和滤波器大小)。
2).当feature map大小减少1倍的时候,blocks的宽度会增大一倍。 - 构建的网络模块
作者提出的构建块如下所示: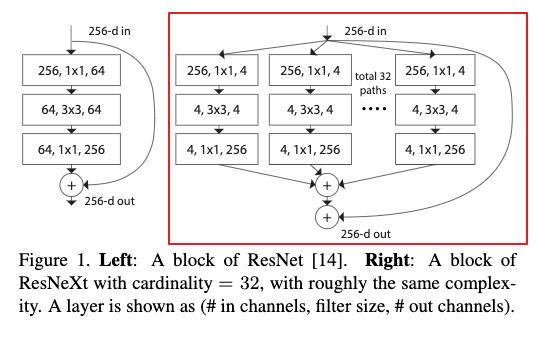
3.2 可以将提出的构建块变成分组卷积的形式
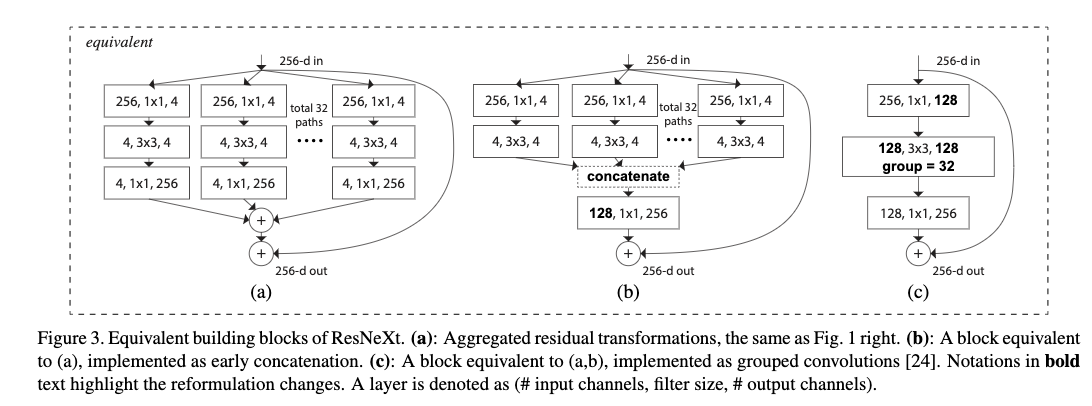
这使得提出构建块很容易实现。可以通过简单的分组卷积的方式来实现提到的构建块。
3.3 网络拓扑结构

3.4 讨论
这里作者使用了相同的转换形式,使得提到的构建块能够通过group 卷积的形式来实现。但是这只是作者提到的构建方法的一个具体的实现。作者提到的构建方式是基于split-transformation-aggregate的方式。变换形式可以多种多样。
四、实验结果及结论
4.1 Imagenet-1k分类任务

Table2给出了相同复杂度下不同组数对应的bottleneck的宽度。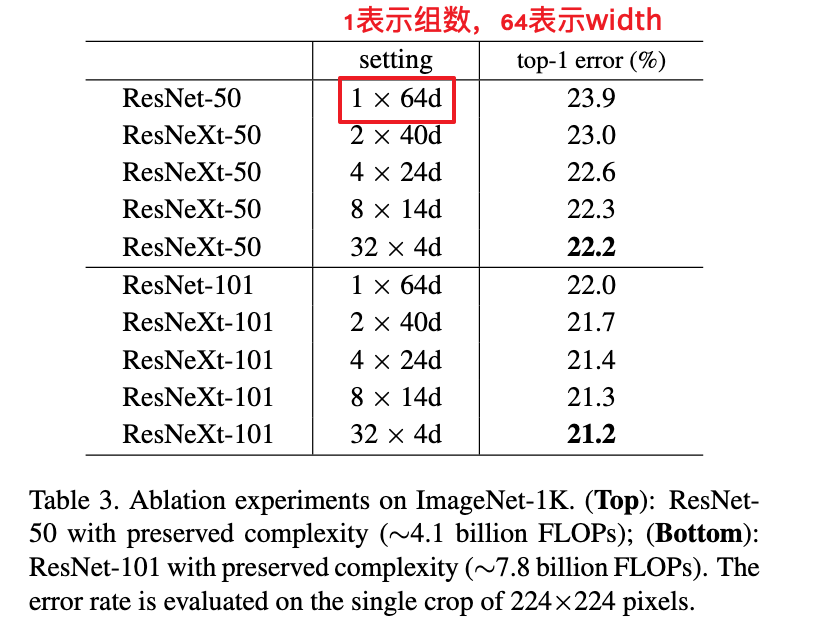
从Table3可以看到在相同复杂度下,随着组数增多,性能也跟着提高。并且随着组数的增加,性能的提高也趋向饱和。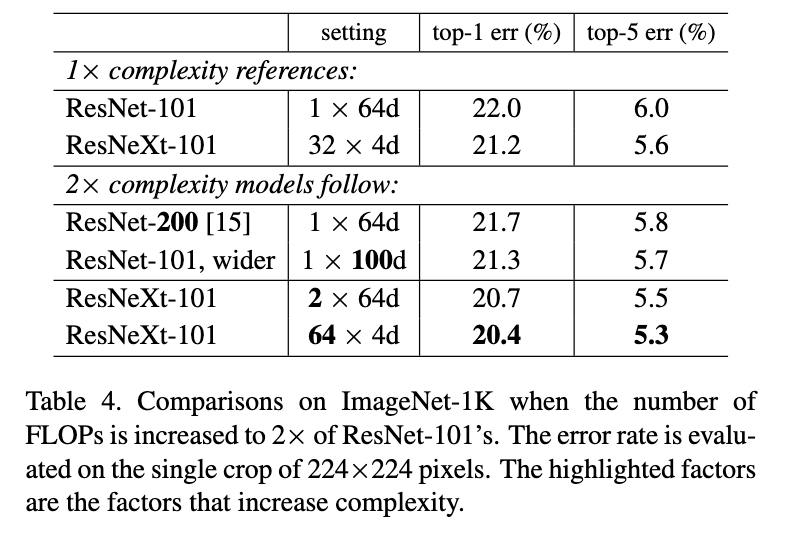
从Table4可以看到相同复杂度下提高深度或者宽度带来的性能提升并没有提高分组好;并且即使在增加的复杂度只有使用宽度和深度增加的复杂度的50%的时候,使用分组卷积仍然比他们好。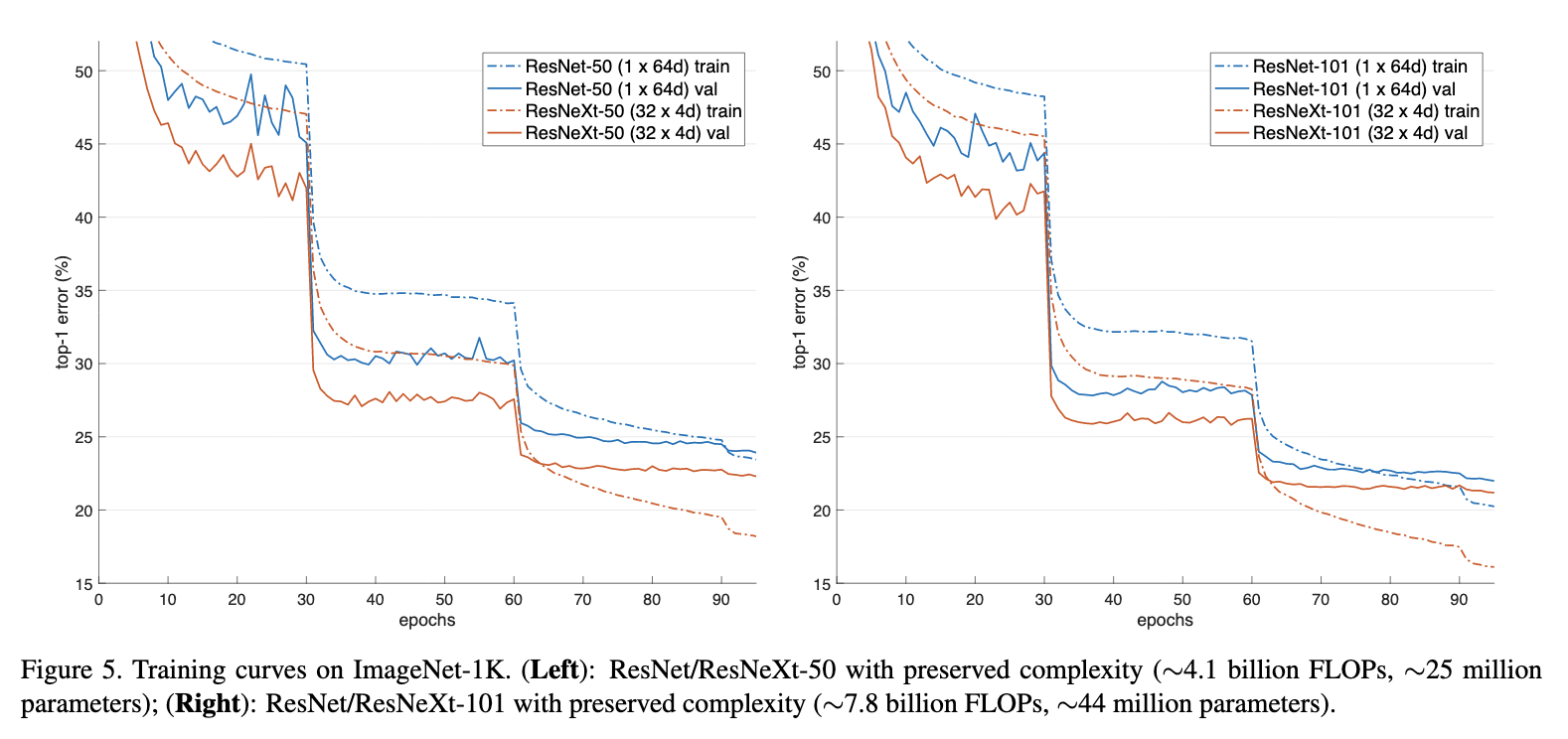
Figure5为各个模型训练的误差曲线
在移除short cut的情况下,不使用分组比使用分组卷积性能下降更严重。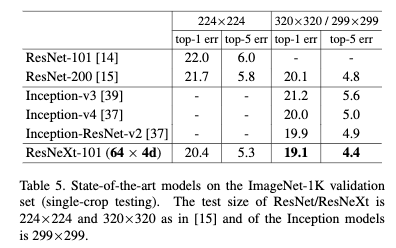
Table5为ResNeXt与跟其它最先进方法的比较。
4.2 ImageNet-5k分类任务
该数据集是整个ImageNet-22k的一个子集,该数据集包括了ImageNet-1k和额外的4k个类别。整个数据集有680万张图片,大概是ImageNet-1k的5倍。由于没有官方的训练集和验证集的划分方式,作者使用了ImageNet-1k的验证集来验证。实验细节与ImageNet-1k一致。作者采用从头开始训练的方式。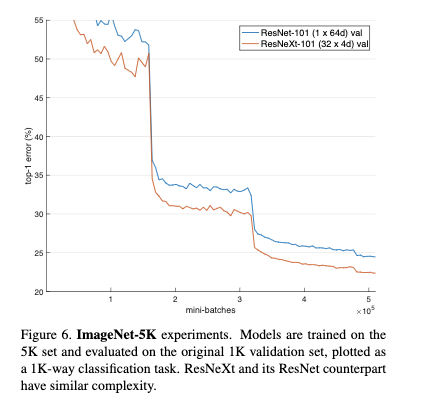
Figure6给出训练的误差曲线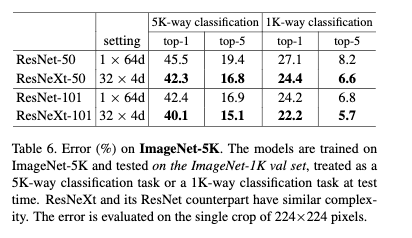
这里验证集采用将其它类别抛弃只对1k个类别使用softmax的方式。从Table6的结果可以看到尽管复杂度差不多,但是ResNeXt具有更强的模型表达能力,并且在验证集上达到更好的效果。
4.3 CIFAR分类任务
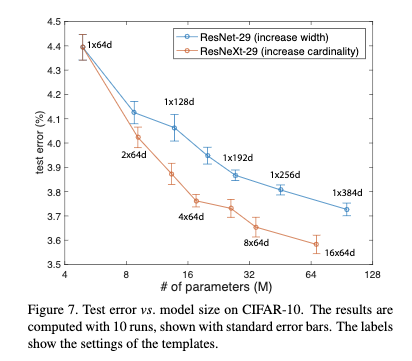
从Figure7可以看出增加组数比增加宽度对性能的提高更加明显。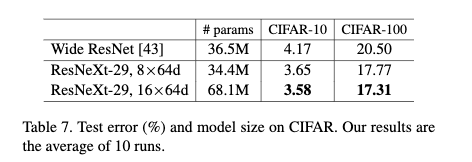
从Table7可以看出在同等复杂度下,ResNeXt要比Wide ResNet要好。
4.4 coco目标检测任务
作者使用COCO trainval-115k来训练,并使用val-5k来测试。评估方式为coco-style AP和AP@IOU=0.5。检出框架采用faster rcnn,backbone使用ResNet/ResNeXt。backbone先在ImageNet-1K分类任务上进行预训练,然后在检出数据集上进行finetune。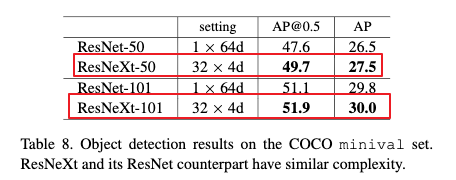
Table8为ResNet和ResNeXt在COCO目标检测任务上的对比结果。从Table8可以看出ResNeXt要比ResNet性能更好。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_Aggregated Residual Transformations for Deep Neural Networks_CVPR2017_XieS et al
文章字数:1.5k
本文作者:xieweihao
发布时间:2018-01-22, 18:14:04
最后更新:2020-01-23, 10:20:18
原始链接:http://weihaoxie.com/post/e3ea9c19.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

