2014_SPPnet_Spatial pyramid pooling in Deep convolutional networks for visual recognition(ECCV2014)Kaiming He
一、背景及意义(动机)
先前针对分类的卷积神经网络需要固定大小的输入,这样需要对不同尺度的图片进行裁剪或者变形之后输入,这种做法会导致目标信息丢失或者带来不期望的图像扭曲,另外预定义的尺度对于不同的目标可能会不合适。这两个问题往往会降低准确率。如果能够解决这些问题,就有可能可以进一步提高分类准确率。
二、使用什么方法来解决问题(创新点)
针对这个问题,作者分析了为什么需要固定大小输入的原因,那是因为全连接层需要固定大小输入,为此作者提出了一个解决方案叫空间金字塔pooling,作者称其为SPPnet,它被加在最后一层卷积层上,将最后一层的卷积特征池化成固定大小的输出,为此它可以对输入的任意尺度大小的图片生成固定长度的表示。
- spp的好处(作者通过实验验证了每个优点都对准确率的提高有帮助)
1)不管输入图片大小如何,都可以生成固定大小的特征。
2)它将特征拆分成不同粒度的bin,类似于应用了多个不同尺度的slide window,相较于单个尺度的slide window,这种方式对目标的形变更加鲁棒
3)应用于不同粒度的slide window可以根据输入图像的大小进行自适应的变化。 - 技巧及重要结论
1)使用多层pooling提高了准确率。提升的主要原因是多层的金字塔层对于目标的形变以及在空间中的布局更加鲁棒。
2)这种方式不仅可以用于多尺度测试,也可以用于多尺度的训练方式。多尺度的训练,在训练集上的拟合情况与单尺度类似,但是在测试集上有更高的准确率。具体的做法是一个epoch使用一种尺度来训练。
3)使用全图输入,可以提高准确率。
4)feature map上的多尺度多视角的测试,可以提高准确率。
5) 使用多个模型进行boosting可以提高准确率
6)作者通过实验验证了sppnet的优势与具体的网络结构是不相关的,即证明了该方法的通用性。
7)该方法可以加速R-CNN的特征提取并且能够取得更好或者差不多的检出准确率,应用该方法无论图片中的目标有多少,都只需应用卷积神经网络对整张图片提取一次特征,然后再根据候选目标的位置利用spp从特征图上提取固定维度的特征向量,比起R-CNN,应用该方式可以提高24倍以上。
8)预训练使用的类别数,样本数,以及目标尺度对于结果都有一定的影响。 - 一些重要的细节
1)对于一般的分类网络,训练的时候都需要进行减均值的预处理方式。如果使用多种尺度进行训练,作者的做法是对于Imagenet直接将均值图片resize到目标尺度;对于VOC2007和Caltech101则是直接减去128.
三、方法介绍
空间金字塔pooling是词袋模型(Bow)的一种扩展,它将图片划分成不同粗细粒度的多个部分,然后再对每个部分进行聚合。这种思想其实在传统的计算机视觉任务中一直发挥重要的作用,在深度学习还没有出现之前,它就已经被用在图像分类和检测中。SSP可以说是BOw的一种改进,因为SSP它能够保留空间信息。使用SSP层,网络的输入可以是任意的宽高比,任意的尺度。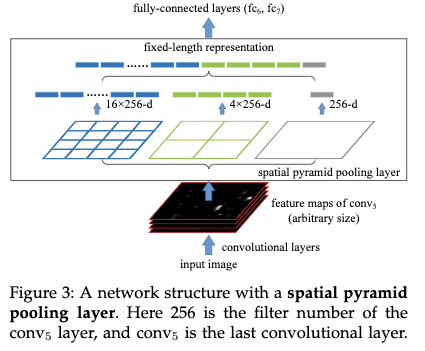
空间金字塔pooling会根据输出的大小,以及金字塔的层数,来决定每个金字塔层pooling的size和stride。比如4X4,2X2,1X1,他会根据pooling输出的大小以及输入的大小来推断每个pooling的size和stride。假设特征图大小为13x13,某一层金字塔层的输出大小为nxn,那么滑动窗口大小为$win=\lfloor a/n \rfloor$,stride大小为$str=\lceil a/n \rceil$.在利用该方式得到每一层金字塔层的特征之后,再将所有的特征拼接在一起。下图给出了一个3层金字塔pooling的例子:
作者也尝试使用了多尺度的训练方式,为了减少不同尺度网络的切换,作者在训练一个epoch的时候,只使用一种尺度来训练。
四、实验结果及重要结论
4.1 分类:
4.1.1 ImageNet分类任务
4.1.1.1 训练细节:
1.训练数据为ImageNet2012,1000类。
2.图像先被按比例resize成小边为256,然后再从图片的中心和四个角crop 224X224大小的图片,共5张。
3.对图片进行水平翻转和颜色增强。
4.再最后两层全链接层中加入dropout
5.开始的学习率设置为0.01,之后当训练loss不降的情况下,再次减少10倍。
6.作者使用了单个6g显存的GPU,训练了2到4周。
7.使用了4层金字塔。6X6,3X3,2X2,1X1
8.使用的网络结构有4种,ZF-5,Convent*-5,Overfeat-5,Overfeat-7
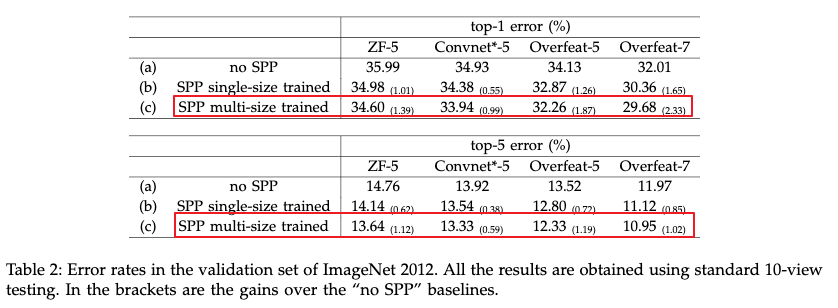
4.1.1.1 实验结果及结论
- 使用多层pooling提高了准确率。提升的主要原因是多层的金字塔层对于目标的形变以及在空间中的布局更加鲁棒。
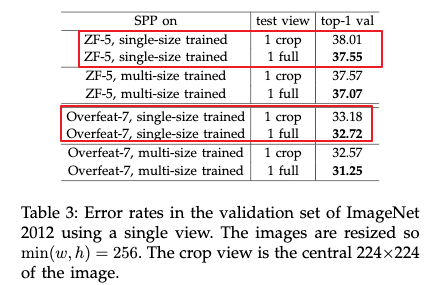
作者使用了单尺度的训练方式,在训练和测试的时候都使用了224X224,每张图片先resize到256X256,然后从四个角落和中心crop224X224,最后再结合翻转,构建10张训练和测试图片。测试的时候对这十张图片进行求平均。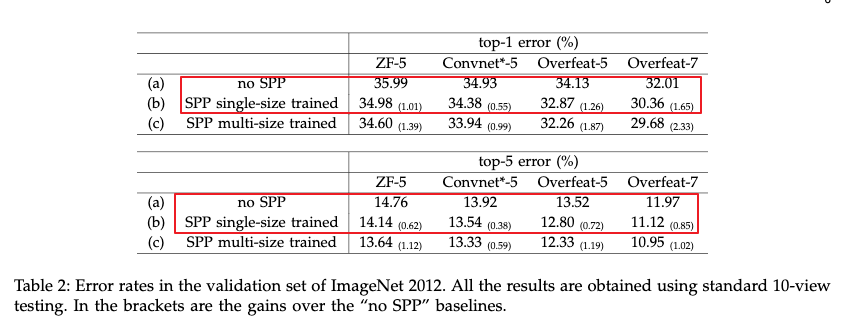
- 使用多个不同尺度的图片进行训练,提高了准确率。作者将图片resize到不同尺度,然后进行训练。训练的时候使用了两个尺度224和180。测试的时候仍然使用单个尺度224.然后仍然将图片resize到256后进行crop,每张图片构建新的10张图片。最后得到的结果比起单尺度的训练方式要更好。作者也尝试使用从[180,224],之间抽取的一个随机尺度来训练。发现结果比起只使用两个尺度的要差,但是仍然比使用一个尺度的要好。可能的原因是测试的时候是224,而使用随机尺度的话,抽取的尺度很多都不是224,跟测试数据的分布有所偏差。
- 使用全图输入,可以提高准确率。作者将图片resize成短边为256,并保持宽高比不变。训练的时候仍然使用单尺度的训练。作者比较了中心crop和保留宽高比的效果,发现使用整张图片的效果更好。虽然使用整张图片比使用单个尺度多个视角的要差,但是当把他们结合在一起的时候仍然可以进一步提高多视角的准确率。并且提取的特征质量会更好。
- feature map上的多尺度多视角的测试,可以提高准确率。作者将图片的短边resize到256,然后保留图片的宽高比,并从feature map上提取多个视角的特征用于测试,然后求平均。最后与在图片上的多个视角的测试进行对比,发现他们差不多。然后作者又使用多个尺度多个视角的测试,每个尺度提取18个视角,中心,四个角落,四个每个边的中心,整张图片,以及他们的水平翻转。作者通过多视角多尺度的方式,又将准确率进一步提高。
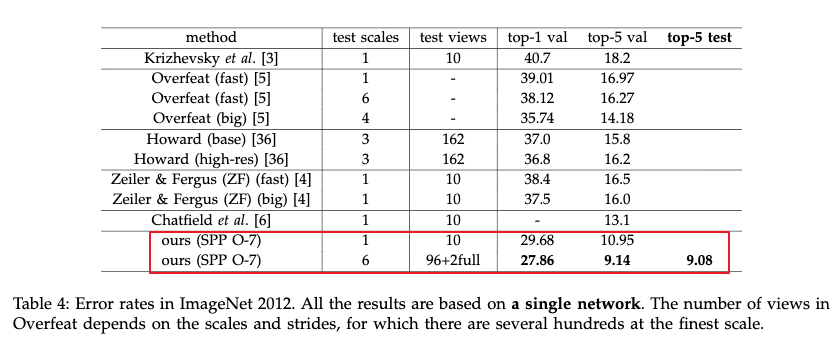 Krizhevsky的方法取得了ILSVRC2012比赛的冠军,而Overfeat,Howard,Zeiler&Fergus则是ILSVRC2013比赛的最好的几个方法。
Krizhevsky的方法取得了ILSVRC2012比赛的冠军,而Overfeat,Howard,Zeiler&Fergus则是ILSVRC2013比赛的最好的几个方法。 - 使用多个模型进行boosting可以提高准确率
下图是ILSVRC2014比赛的排名情况,作者使用了7个模型进行融合使得结果进一步提升。并取得第三名的成绩。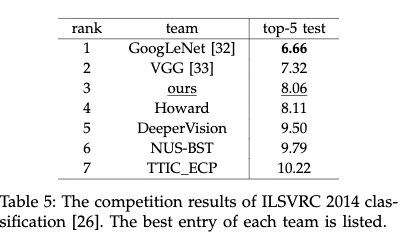
4.1.2 VOC2007分类任务
4.1.2.1 训练细节
- 训练数据包括9963张图片,共20个类别。其中5011张图片用于训练,剩下的图片用于测试。性能评估方式使用mAP(mean Average Precision)
- 作者使用在ImageNet进行训练的网络来提取图片的特征,然后将这些特征用于重新训练SVM分类模型,训练的时候没有做任何数据增强,只对特征进行L2标准化。
4.1.2.2 实验结果和结论
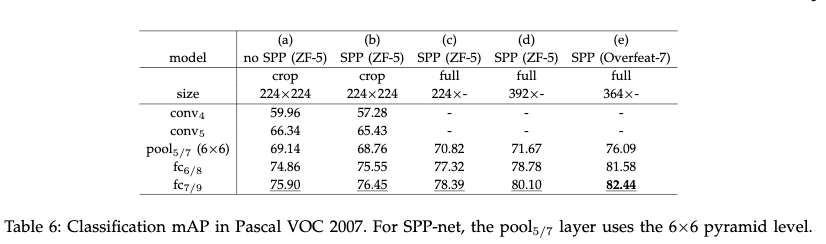
- 图中a列表明:越深层的特征越好
- 图中a,b列表明:使用fc层的特征获得更好的增益,主要由于多层的pooling
- 图中c列表明:全图输入的特征更好
- 图中d列使用尺度392更好的原因主要是:在VOC2007中目标比较小,而在Imagenet中目标比较大。这个结果表明:目标尺度会影响到分类的准确率,而SPP-net可以部分处理这个尺度不匹配的问题。
- 图中e列为将网络结构替换为Overfeat-7,并使用多尺度训练得到的结果
4.1.3 Caltech101 分类任务
4.1.3.1 训练细节(没有说清楚怎么训练)
- 该数据集包括了9144张图片,共102个类别,其中1个是背景。
- 作者从每个类别中随机抽取30张图片用于训练,抽取50张图片以上用于测试。作者按照这种数据划分方式重复了10次,并将结果取平均,作为最后的结果。
4.1.3.2 实验结果和结论
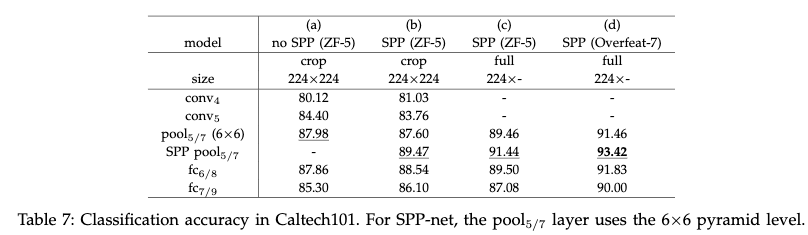
- 从结果来看Caltech101与voc2007有类似的结果:
- 从a,b可以看出spp-net要比no-spp net效果要好
- 从c,b可以看出全图输入要比crop好
- 但是也有一些不同的结论:
- 在Caltech101分类任务中全连接层的准确率要比spp层低。
- 在选择的多个测试尺度中224的尺度是最好的,这个主要是因为在Caltech101中,目标占据图像的区域与ImageNet差不多。
- 作者也尝试将图片reshape 成224X224,这样虽然保留了全图信息,但是会带来扭曲。从结果来看效果没有使用全图的好。使用reshape的准确率是89.91%,而使用全图输入没有扭曲的准确率达到91.44%。
下图给出了不同方法在Voc2007分类数据集和Caltech101分类数据集上的结果。其中VQ,LCC,FK都是基于金字塔匹配的,剩下都是基于深度网络的。在基于深度网络的方法中,Oquab等人的方法和Chatfield等人的方法采用了finetune和多视角的测试。本文提到的方法只采用了单张全图,并且没有使用finetune,但是取得了与他们类似的结果。而在Caltech101测试集上,作者提出的方法远远超出当前最好的方法。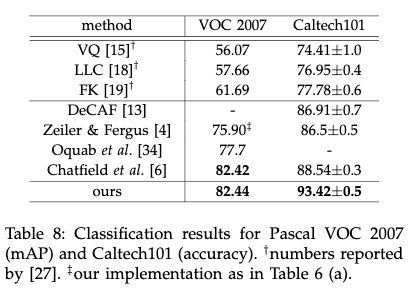
4.2 检测:
4.2.1 RCNN方法简介
- R-CNN首先利用selective serach从每张图片中提取约2000个候选窗。
- 然后将每个候选窗reshape成227X227,并利用一个预先训练好的卷积网络去提取特征。
- 利用提取到的特征去训练一个2分类的SVM分类器。
虽然RCNN相对于先前的方法,效果很好,但是速度比较慢,每张图片需要对2000个候选窗口应用卷积网络去提取特征。特征提取是测试速度的主要瓶颈。
4.2.2 将SPP应用于RCNN中及训练细节
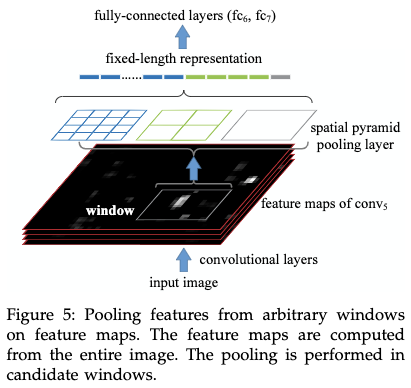
作者将空间金字塔pooling应用到R-CNN中,可以提高训练和测试的速度,并且提高准确率。具体的:
1)使用“fast”模式的selective search从每张图片中提取2000个候选框
2)将图片resize到min(w,h)=s
3)利用单尺度训练的ZF-5网络直接提取整张图片的特征。
4)利用4层空间金字塔pooling提取每个候选框的特征,生成12800维的特征向量。
5)最后利用全链接层的特征提供给svm分类器,然后利用每个类别的svm分类器来得到每个类别的得分。训练svm的时候,作者使用了ground-truth作为正样本,使用与ground truth的IOU小于0.3的候选框作为负样本。并且负样本之间的IOU要小于0.7.最后使用hard negative mining的方式来训练svm,困难样本挖掘只迭代一次。
6)在测试阶段,在对每个候选框进行打分之后,作者使用了非最大化抑制的方式阈值为0.3,去除掉一些冗余的框。使用该方式,利用多尺度进行测试,可以进一步提高效果。作者发现,最好的一种方式是,对于不同尺度的候选窗口,只对该尺度下最接近224X224的候选窗口进行特征提取。 这样的话不同尺度的输入只需跑一次卷积神经网络对全图进行特征提取,然后让各个候选窗口按在该尺度下最接近224X224的原则分配到各个尺度下,然后应用spp对候选窗口进行特征提取。
作者也尝试使用fine-tune和bounding box回归。
1.fine-tune的时候作者只fine-tune全链接层,固定其他层。
2.fc8使用了方差为0.01的高斯分布来进行初始化。
3.正样本为IOU大于0.5,负样本为与正样本的IOU小于0.5大于等于0.1,每个batch包括1/4的正样本,3/4的负样本。
4.开始250k次迭代使用学习率为0.0001,之后50k次迭代的学习率设置为0.00001
5.使用bounding box 回归作为后处理方式。使用的特征是来自与conv5的空间金字塔pooling。使用的样本为IOU大于0.5的候选框。
4.2.3 实验结果和结论
4.2.3.1 VOC 2007测试集
1. 实验结果
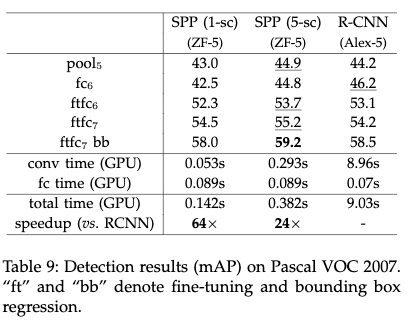
- R-CNN使用Alex-5
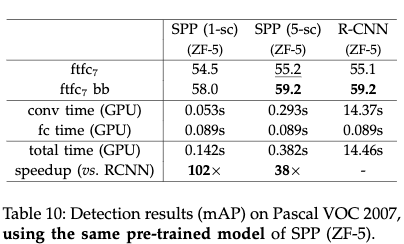
- R-CNN使用ZF-5
- 不同的目标检测方法在20类目标的map
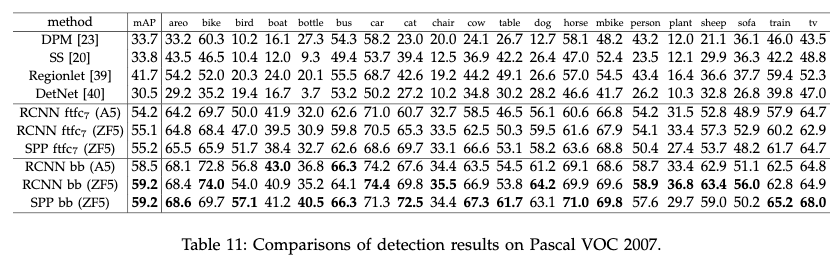 作者使用另外一种候选生成方式EdgeBoxes进行测试,mAP为52.8.这是因为训练的时候使用的是Seletive search。当训练的时候同时使用Selective search和EdgeBoxes,测试时使用EdgeBoxes时,mAP达到了56.3.这是因为训练样本增加了。
作者使用另外一种候选生成方式EdgeBoxes进行测试,mAP为52.8.这是因为训练的时候使用的是Seletive search。当训练的时候同时使用Selective search和EdgeBoxes,测试时使用EdgeBoxes时,mAP达到了56.3.这是因为训练样本增加了。
2. 结论
从结果来看,SPP跟RCNN差不多,但是速度方面SPP要比RCNN快很多。
- 通过模型组合可以提高效果
作者使用相同的网络结构,不同的初始化方式在ImageNet上训练了另一个网络,然后重复上面的检测算法,另一个网络在整体的mAP上与原先的差不多,但是有11个类别要比原来好。两个模型存在较大的差异,可以互补,所以融合后效果提升了不少。
组合方式为:首先使用两个模型分别为测试图片上的所有候选进行打分;然后将结果合并在一起做非最大化抑制。
作者进一步发现模型组合的提升主要来自与卷积层。作者使用同个模型不同初始化方式对整个卷积网络进行finetune得到了提升,但是使用同个模型不同的初始化方式来fine-tune全连接没有提升。说明提升主要来自于卷积层。
4.2.3.2 ILSVRC 2014测试集
1. 训练细节
- ILSVRC 2014检测数据集,包括200个类别。不允许使用imagenet 1000类数据集。
- 450k训练数据;20k验证数据;40k测试数据
- 由于数据量以及类别数都比image net要少,这样的话性能没有使用imagenet来预训练好。为此作者使用了提供的499类的数据集。
- 由于目标尺度的分布在499类的CLS上是0.8,而在DET是0.5,为此作者把DET数据集resize成min(w,h)=400,而不是256.然后随机crop 224X224用于训练,只有当它与ground truth的重叠大于0.5时,才用来训练。
2. 重要结论:
类别数,样本数,以及目标尺度对于结果都有一定的影响。
作者对比了利用ILSVRC2014数据集的不同标签(大类标签有200,子类标签有499)来进行预训练的情况下,在Pascal VOC数据集上的检出效果。作者使用了pool5特征进行训练,在使用imagenet进行预训练的情况下,mAP是43.0%,在使用ILSVRC2014 200类进行与训练的情况下,mAP降到了32.7%,而使用ILSVRC2014 499类进行预训练的情况下,mAP提高到了35.9%。从结果来看,虽然使用200类和499类训练数据量并没有变化,但是效果却提升了,说明更多的类别有助于提高特征的质量。另外作者尝试了使用min(W,H)=400来训练,替代使用256来训练,mAP进一步提高到了37.8%。但是仍然没有使用imagenet进行预训练的好,说明数据量对于深度学习的重要性。通过模型的组合可以进一步提升效果。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2014_SPPnet_Spatial pyramid pooling in Deep convolutional networks for visual recognition(ECCV2014)Kaiming He
文章字数:4.5k
本文作者:xieweihao
发布时间:2016-11-11, 22:01:15
最后更新:2020-01-23, 10:11:31
原始链接:http://weihaoxie.com/post/60c293cd.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

