2014_Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR2014)Ross Girshick
一、背景及意义(动机)
这篇论文中作者提出了一个很牛逼的目标检测算法R-CNN,直接将PASCAL VOC数据集上的最好性能提高了30%。将深度学习应用到目标检测,主要会面临两个挑战,一个是如何使用深度学习去定位目标位置;另一个是在数据缺乏的情况下如何训练高质量的模型。在这个方法中作者结合了两个关键的思想来解决这两个问题:1)为了去定位和分割目标,可以应用一个能力很强的卷积神经网络去筛选候选目标 2)当标注的训练数据缺乏的情况下,运用辅助任务进行监督预训练和指定任务的fine-tune,可以让性能有一定的提升。
二、使用什么方法来解决问题(创新点)
- 创新点
1)提出一个能有效进行目标检出的框架RCNN,在PASCAL VOC 2012数据集上,将mAP提高30%
2)当标注的训练数据缺乏的情况下,运用辅助任务进行监督预训练和指定任务的fine-tune,可以让性能有一定的提升。将mAP提高了8个点。 - 存在的问题
1)需要对候选区域的特征进行存储,需要较多存储空间
2)对每个候选区域都需要运行一次卷积神经网络来提取特征,速度慢 - 重要结论
1)对于深层神经网络来说,越高层的特征越是任务相关的,而低层的特征则更加的通用。
三、方法介绍

3.1 R-CNN主要包括了3个模块:
- 首先通过一个类别无关的proposal方法得到候选框。
这里proposal方法作者主要使用了selective search,从每张图片中提取2000个候选框。 - 然后将候选框reshape到指定输入大小并用一个卷积神经网络提取固定长度的特征。最后利用SVM来对每个目标进行打分,每个类别训练一个svm。
特征的提取主要使用了一个卷积神经网络,从每个区域提取4096维的特征。输入图片大小为227X227,预处理方式为减去均值图片,网络结构为5层卷积2层全连接层。 - 最后对每个类别运用非最大化抑制将冗余的检测框剔除掉。非最大化抑制主要是先找到得到最高的目标,如果它周围的目标的得分超过类别阈值,但是它与最好得分目标的IOU超过了某个阈值,那么将该目标剔除掉。
3.2 监督预训练和指定领域的finetune
- 监督预训练:作者使用了ILSVRC2012作为辅助的数据集,并利用该数据集图像层面的标注训练一个分类模型。
- 在检出训练集上进行finetune:将最后一层分类层替换为N+1类,其中1类为背景。将候选框与目标的IOU大于等于0.5作为正样本,其他作为负样本。利用先前的预训练模型来fine-tune,并把学习率设为原来的十分之一为0.001.在每次迭代中,均匀采阳32个正样本和96个负样本,batchsize大小为128。
3.3 目标类别分类器
- fine-tune完之后,作者没有使用finetune的网络的结果作为最终的结果。而是利用fine-tune完成的网络作为特征提取器,并运用histogram intersection kernel svm分类器,来得到最终每个目标的类别。这里作者训练svm的时候将训练集和验证集一起拿来训练。
- 这里负样本如何确定很关键,当使用IOU小于0.5为负样本时,mAP下降5个点,使用IOU
为0时为负样本,mAP下降4个点,最终作者通过网格搜索确定了IOU小于0.3为负样本最优。正样本则为ground-truth bounding boxes。 - 最后作者采用hard negative mining方法来加速拟合。通过利用困难负样本挖掘,只需要跑一个epoch,svm就拟合完成了。
四、实验结果及重要结论
4.1 PASCAL VOC 2010-12测试集
对于VOC2010-12,作者使用VOC2012训练集进行finetune,使用VOC2012训练集和验证集训练SVM模型。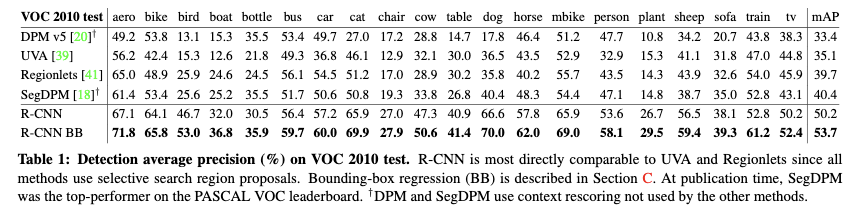
4.2 ILSVRC2013检测数据集
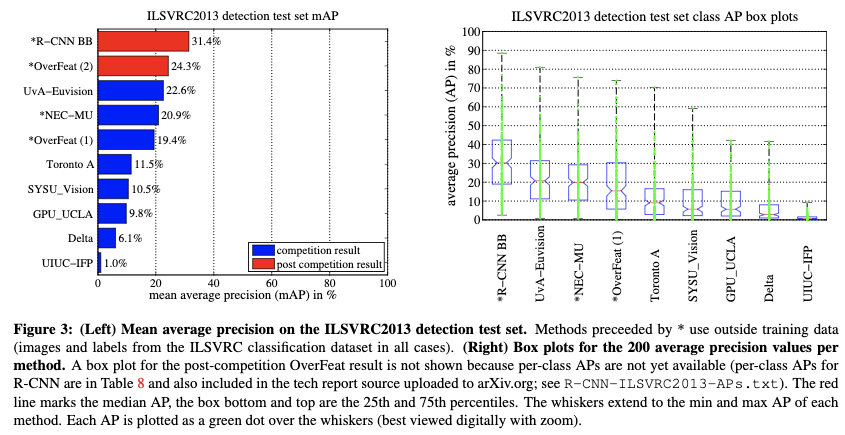
在ILSVRC2013检测数据集上,OverFeat,NEC-MU,UvAEuvision,Toronto A 和UIUC-IFP都使用了卷积神经网络,但是效果却比作者的方法差很多,说明不同的用法对结果影响很大。
4.3 可视化学习到的特征

作者选取了pool5层中6个激活单元,作为proposal的得分,执行非最大化抑制,最后对所有的结果精细排序,选择了激活值最大的前16个图片进行可视化。说明学习到的特征具有较好的判别性。
4.4 Ablation studies
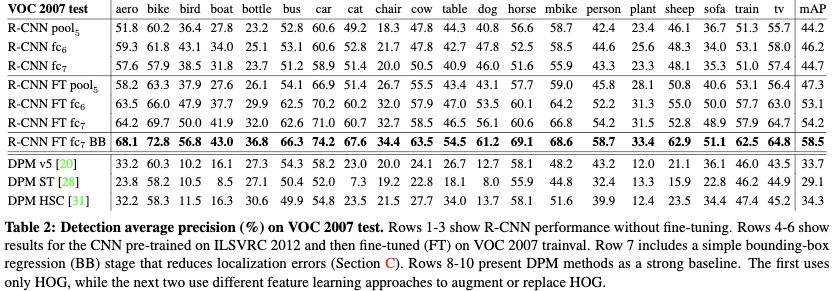
作者对fine-tune与不fine-tune不同网络层的特征进行了比对,发现pool5的特征相对于fc层比较通用,而fc层的特征则更多是任务相关的。
4.4.1 在没有fine-tuning的情况下,比较不同层特征带来的效果。
- 为了理解哪一层特征对于检出性能比较关键,作者分别用CNN(只使用ILSVRC2012进行预训练)的最后3层来测试VOC2007数据集上检出任务的效果。结果表明:pool5只使用了卷积特征就可以达到较好的效果,说明主要带来效果的是卷积层而不是全连接层;另外fc7要比fc6效果差,说明越高层的特征越是任务相关的。
4.4.2 在fine-tuning的情况下,比较不同层特征带来的效果。
- 利用VOC2007trainval集对模型进行finetune,并利用finetune好的模型的最后3层来测试VOC2007数据集上检出任务的效果。利用finetune后的特征来训练,mAP的提升十分明显,足足提升了8个点。finetune后fc6和fc7比起pool5层提升的效果更加明显,进一步说明越高层的特征越是任务相关的,而低层特征则是更加的通用。
4.4.3 不同网络结构对结果的影响

T-net比O-net效果更好,但是也更加耗时
4.4.4 使用Bounding-box 回归可以提高定位的准确率
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2014_Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR2014)Ross Girshick
文章字数:1.6k
本文作者:xieweihao
发布时间:2016-11-10, 21:03:14
最后更新:2020-01-23, 15:00:30
原始链接:http://weihaoxie.com/post/2f9d64a9.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

