2018_An Analysis of Scale Invariance in Object Detection - SNIP_CVPR2018(oral)_SinghB_DavisL
一、背景及意义(动机)
当前在ImageNet1000类分类任务上top5误差已经降低到2%;但是在COCO目标检测任务上,在overlap为50%的情况下mAP也只有60%。这个巨大的差距主要是由于COCO目标检测数据集中目标的尺度范围很大,并且存在大量的小目标。Fig1给出了COCO和ImageNet数据集中ROI区域相对于图像的比例,在整个数据集中的占比情况。从Fig1可以看出在COCO数据集中目标的尺度跨度很大,在COCO数据集中,有10%的ROI占图像的比例小于0.024,有90%的ROI占图像的比例小于0.472,而这中间目标尺度的跨度接近20倍,目标检测器想要对这么大的尺度范围的目标都有效是很困难的,特别是小目标;从Fig1中也可以看出ImageNet数据集和COCO数据集目标尺度的差异是很大的,这也会降低利用Imagenet进行预训练的效果。为了验证是否upsample能够更好的处理小目标及为了缓解尺度范围跨度较大的问题该如何选择不同的分辨率,不同的尺度范围来训练,作者进行了两个探究性试验。基于对这两个探究性实验的分析作者得出的结论是训练检测器的时候最好是使用特定的尺度范围内的目标来训练,但是要尽可能多的保留所有的目标外形和姿势等信息。为此作者提出了用于图像金字塔的尺度标准化训练框架(SNIP)。该框架使用多种分辨率的图像进行训练,并对于各个图像金字塔层只使用该金字塔层指定尺寸范围内的目标进行训练,忽略其它目标;在推断的时候也使用多种分辨率的图像进行测试,每种分辨率只保留指定尺度范围内的目标,然后将这些目标缩放到同个尺度,再利用soft-nms进行过滤。使用该方法,作者在单模型的情况下,在COCO目标检测任务上mAP达到了45.7%,在组合3个模型的情况下mAP达到了48.3%。并赢得了COCO2017的挑战赛。
代码:http://bit.ly/2yXVg4c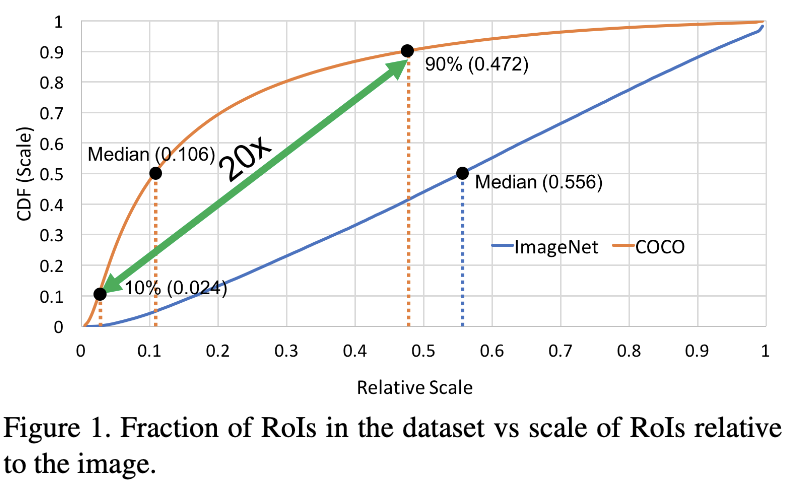
二、使用什么方法来解决问题(创新点)
2.1 这里简单介绍通常处理尺度变化问题的一些解决思路
- 通过dilated convolutions来增加特征图的分辨率的同时维持预训练网络的感受野,从而不会影响到大目标的检测效果
- 训练的时候对图片进行1.5倍或者2倍的upsample,测试的时候对图片进行2倍的upsample。
- 使用多个不同分辨率的卷积层来独立预测目标,如SDP,SSH,MS-CNN。
- 通过组合浅层和深层卷积层来预测目标,如FPN,Mask-RCNN,RetinaNet。
2.2 本文的贡献及创新点
- 通过第一个探究性的实验,揭露了在进行小目标分类的时候,将小目标upsample到预训练网络使用的训练图片尺度来finetune,效果要优于直接使用小尺度的图片来从头开始训练,所以对小目标进行upsample是很重要的。
- 通过第二个探究性的实验,揭露了特定尺度范围的目标检测器虽然可以解决训练和测试的时候尺度的差异带来的负面影响,但是分类器在训练的时候训练的目标大大减少,也会使性能降低;用所有尺度训练的目标检测器虽然训练的目标很多,但是目标跨尺度很大,也给目标检测器的训练带来了难度。
- 基于对两个探究性实验的分析作者得出的结论是训练检测器的时候最好是使用特定的尺度范围内的目标来训练,但是要尽可能多的保留所有的目标外形和姿势等信息。为此作者提出SNIP框架来实现这个目标。
三、方法介绍
3.1 探究性实验为存在的一些问题寻求答案
3.1.1 两个存在的问题
- 为了让目标检测器获得更好的性能,上采样图片是不是关键的呢?
- 在利用预训练的图像分类模型来进行finetune的时候,使用的目标实例的分辨率应该rescale到跟预训练的模型一致呢,还是只需要对图片进行上采样然后使用所有的目标来训练呢?
3.1.2 两个探究性实验
- 通过改变输入图像的尺度,来探究训练和测试的时候尺度差异对分类模型的影响以及为了检测小目标对图像进行上采样好还是直接利用低分辨率来训练更好。
因为目标检测在训练的时候一般会把图像缩放到800 $\times$ 1200,测试的时候为了检测小目标则是把图像缩放到1400 $\times$ 1200,为此作者通过这个实验来探究这种分辨率的差异对性能有什么影响以及上采样对检测小目标是否更好。
 作者设置了3个实验:
作者设置了3个实验:
- 1)多尺度推理:如Fig3 CNN-B所示,该实验通过将原本ImageNet的图像缩放到 48 $\times$ 48,64 $\times$ 64,80 $\times$ 80,96 $\times$ 96,128 $\times$ 128,然后再将图片缩放到224 $\times$ 224,来对使用高分辨率训练的分类器进行多种尺度的测试。Fig4给出了CNN-B top-1的准确率。作者发现随着测试分辨率和训练分辨率差异的增加,性能会不断下降。因此训练和测试图片分辨率的差异确实不是最佳的选择,至少对于图像分类任务是这样。
- 2)使用小目标图像来训练和推理:由于训练和测试图像尺度的差异会影响性能,那么一个比较直接的方式,就是让训练和测试的时候图片的分辨率保持一致。如Fig3 CNN-S所示,作者通过修改ResNet-101网络结构来达到这个目的。作者给出了两种不同尺度下的效果,48 $\times$ 48和96 $\times$ 96。从Fig4可以看出,CNN-S的效果要远远优于CNN-B。因此为了让小目标得到更好的性能,测试和训练的时候尺度保持一致要更好。
- 3)在基于所有尺度训练的分类器思的基础上利用小目标图像来进行finetune:如Fig3 CNN-B-FT所示,作者将小目标图像缩放到预训练网络使用的训练目标的尺度,然后利用缩放后的图片来对预训练的网络进行finetune。如Fig4所示,通过对小目标进行上采样来finetune高分辨率的预训练网络得到的效果要优于直接使用低分辨率来训练和测试。
结论:作者通过第一个探究性试验揭露了通过对小目标进行上采样来finetune所有尺度范围目标训练的的预训练网络得到的效果要优于直接使用小目标图像来训练和测试,这也说明预训练对效果的提升有很大的帮助。
- 通过测试使用不同尺度范围目标训练得到的目标检测器的性能,来探究在训练目标检测器的时候,为了让小目标的检出效果更好该如何选定目标的尺度。
从第一个探究性实验可以看出,训练和测试的图像分辨率的差异会降低性能。而目前的目标检测方法由于受到GPU内存的限制,训练的时候使用了800 $\times$ 1200大小的图片,而测试的时候使用了1400 $\times$ 2000的图像,显然不符合最优的设置。那训练的时候使用什么样的分辨率会对小目标的检测最好呢?为了探究这个问题,作者使用了多种不同的设置来训练目标检测器,而使用分辨率为1400 $\times$ 2000的图片进行测试,来看看对小目标的效果如何(这里的小目标主要是像素小于32 $\times$ 32的目标)。由于Deformable-RFCN是COCO数据上最优的目标检测器,并且也开发了代码,所以在这里作者使用它来做相关的实验。在实验中proposal是利用了公共可获取的Deformable-RFCN检测器在800 $\times$ 1200分辨率下提取的。Deformable-RFCN检测器的RPN网络是使用ResNet101作为backbone,并在分辨率为800 $\times$ 1200的图像上,使用5种anchor尺度训练得到的。proposal的分类,作者使用了以ResNet50作为backbone的Deformable-RFCN,但是删除了Deformable RoIpooling层,改用双线性差值后的RoIPooling,这样做的目的在于减少最后一层滤波器的数量;最后作者使用阈值为0.3的NMS过滤掉冗余的目标。在训练的时候,作者并没有让两部分网络进行联合训练,而是只使用RPN网络的结果来训练ResNet-50,主要是为了减少训练时间和节省GPU内存。
作者在这里做了如下3个实验:
- 1)使用不同的分辨率进行训练:在这个实验里,作者使用了两种不同的分辨率训练了2个检测器,一个使用了800 $\times$ 1400的图片,一个使用了1400 $\times$ 2000的图片,在这里分别记为$800_all$和$1400_all$。从Table1中可以看出,如所期望的一样,使用1400 $\times$ 2000的图片训练的检测器要更优。但是提高的性能是很小的。这主要是因为,在分辨率为1400 $\times$ 2000的情况下,大尺度的目标由于太大很难去分类,使得最终对于小目标的效果并没有那么明显。
- 2)特定尺度范围的检出器:为了消除过大目标的影响,作者在该实验里使用了1400 $\times$ 2000的图片,但是忽略了像素大于80 $\times$ 80的目标。从Table1中可以看出,最后的结果要比$800_all$差很多,这主要是忽略的中等和大的目标使得很多姿势和外形信息被丢弃了(大概30%的目标实例被丢弃),从而影响到最终检出器的性能。
- 3)多尺度的训练(MST):在这个实验中作者评估了在训练目标检测器时经常用到的多尺度的训练方式,该方式使用在多种分辨率中随机选择的图片来训练目标检测器,从而得到尺度不变的目标检测器。该训练方式虽然使用了多种不同的分辨率,但是同时也受到了极度大和极度小的目标的影响,使得最终的性能与$800_all$类似。
结论:作者通过第二个探究性的试验揭露了特定尺度范围的目标检测器虽然可以解决训练和测试的时候尺度的差异带来的负面影响,但是分类器在训练的时候训练的目标大大减少,也会使性能降低;用所有尺度训练的目标检测器虽然训练的目标很多,但是目标跨尺度很大,也给目标检测器的训练带来了难度。最后作者得出的结论是,训练检测器的时候最好是使用特定的尺度范围内的目标来训练,但是要尽可能多的保留所有的目标外形和姿势等信息。作者提到的训练框架也正是同时满足了这两点,并使得性能得到很大的提高。
3.2 提到的训练框架
通过上面两个探究性的实验,作者提出了一个新颖的训练框架,用于图像金字塔的尺度标准化方法(SNIP),该方法可以消除在使用分类网络进行finetune的时候,两个任务训练目标的尺度偏差,也可以在使用特定尺度范围内的目标来进行训练的时候,不会减少训练样本的数量。这里尺度的偏差通过图像金字塔的方式来解决而不是一个特定范围的目标检测器。通过图像金字塔的形式将目标尺度标准化到某个范围内,然后在训练的时候只使用与预训练的CNN的训练目标尺度在同个范围内的目标进行训练。通过这种方式可以有效的利用所有目标,该方法也可以应用到不同的任务上,如实例分割,姿势估计,时空活动识别等等,识别的目标的尺度有很大变化的各种问题上。作者通过该方式,将目标检测的性能提高了3.5%,与Deformable-RFCN集成更是将IOU50%的mAP提高7.4%。通过该方法也证明了,比起提供更多的各种尺度的数据来处理尺度跨越较大的问题,CNN更加能够处理特定尺度范围内的识别问题。
3.2.1 SNIP
SNIP是多尺度训练的改进版本,它只使用了与预训练的模型尺度一致的目标,典型的是224$\times$224。在图像金字塔中,在分辨率较高的金字塔层过大的目标很难训练,在分辨率较低的金字塔层过小的目标很难训练,但是这些过小过大的目标在某个金字塔层的尺度是相对合适的。所以SNIP主要是利用图像金字塔中落到指定范围内的目标来训练,而忽略不在该范围内的目标。由于落在图像金字塔中的同个目标,总有一个的尺度在指定的范围内,所以训练的时候不会损失外形和姿势信息,同时也减少了预训练模型训练图像中的目标尺度与目标检测任务中图像中的目标尺度的差异。从Table1中可以看出,SNIP要比其他训练方式要好很多。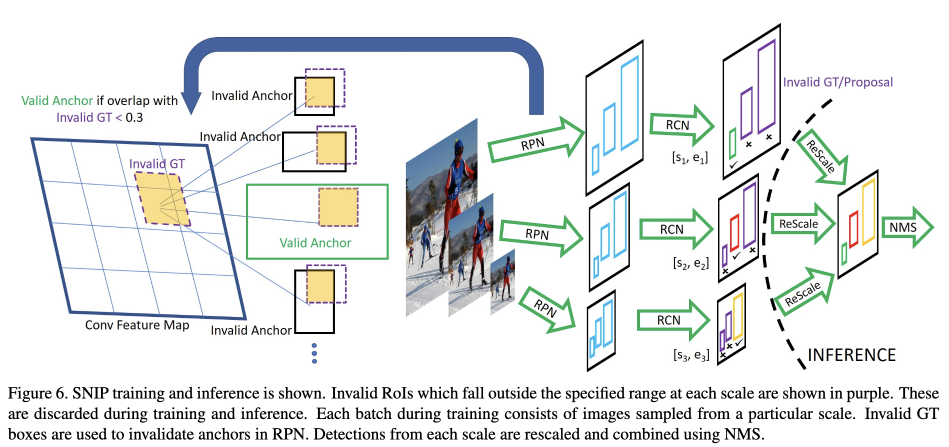
Fig6给出了SNIP的整个框架。该方法在训练proposals分类器的时候,抛弃了在特定的分辨率下不在指定尺度范围内的proposal和grounth box。这里在指定范围内的被视为有效,不在指定范围内被视为无效。一般对于分辨率较高的图片,指定尺度范围为原分辨率图片中尺度较小的图片,而对于分辨率较低的图片,指定尺度范围为原分辨率图片中尺度较大的图片。类似的,在训练RPN网络的时候,作者使用了所有的grounth box,但是当anchor与无效的grounth box的IOU大于0.3的时候,该anchor被视为无效,从而不会用于训练。在推理的时候,对于不同分辨率的图像,首先使用RPN网络提取proposals;然后使用proposals分类器对目标进行精细分类和定位,并抛弃不在指定范围内的目标。最后将不同分辨率下的目标统一到统一的尺度下并使用soft-NMS过滤掉冗余的目标,得到最终的检出结果。
3.2.2 对高分辨率图像进行子图采样
由于在使用较为复杂的网络结构对高分辨率的图像进行训练的时候需要很大的显存,为了缓解显存消耗过大的问题,作者对高分辨率的图像进行随机裁剪,并选取包含目标最多那个图像用于训练。作者只对分辨率为1400 $\times$ 2000的金字塔层执行该操作,从中随机裁剪50个1000 $\times$ 1000的子图,然后选择包含最多目标的图像用于训练,对于不包含有效尺度范围的图片则不需要执行该操作,因为里面的所有目标都不用于训练。对于没有被采集到的有效目标,重复执行该操作直到所有有效的目标都被采集到。最后大约每张图片生成1.7张子图。这种方式只是为了在显存受限的情况下,能够支持复杂网络的训练,而不是为了获得性能的提高。作者使用resnet-50验证了使用子图和原图的效果,发现性能并没有变化。
四、实验结果及重要结论
作者在COCO数据集上验证了提到的方法的有效性。COCO数据集包含了123000张训练图片和20288张测试图片。由于测试图片的grounth truth并没有公开,所以为了更加快速地进行实验,作者只使用训练集中的118000张图片进行训练,然后使用剩下的5000张图片(minival-set)来测试。本文中作者提到的小目标是指像素小于32 $\times$ 32的目标,中等目标是指像素范围在32 $\times$ 32到96 $\times$ 96的目标,大目标是指像素大于96 $\times$ 96的目标。
4.1 训练细节
- 作者使用Deformable-RFCN作为实验的检出器,并使用3个图像金字塔层,分辨率分别为(480,800)、(800,1200)、(1400,2000)。这里的尺度大小是由数据集决定的,480是最短的短边,2000是最长的长边。
- 作者在实验的时候并没有让RPN和RCN网络联合训练,为了能够更快地去尝试不同的分类网络结构,作者将他们分开训练。
- 分类器作者训练7个epcoh,RPN网络则训练6个epoch。
- 作者在前2000次迭代先使用学习率为0.0005进行warmup,然后再调整学习为0.005,并在分类网络和RPN网络分别训练到5.33个epoch和4.33个epoch的时候将学习率减半。
- 对于分类器,作者在图像分辨率为(1400,2000)的时候,将在原本图像分辨率下尺度在[0,80]范围内的目标认为是有效的目标;在图像分辨率为(800,1200)的时候,将在原本图像分辨率下尺度在[40,160]范围内的目标认为是有效的目标;在图像分辨率为(480,800)的时候,将在原本图像分辨率下尺度在[120,无穷大]范围内的目标认为是有效的目标。这些尺度范围主要是基于预训练模型的训练目标尺度来决定的,通过合适的选择可以消除预训练模型和finetune所使用的目标尺度的差异。
- 对于RPN网络,作者在分辨率为(800,1200)的时候,将在原本图像分辨率下尺度在[0,160]范围内的目标认为是有效的目标。其它分辨率的有效范围同分类器。
- 推断的时候,对于分类器,不同分辨率下的有效范围由minival set决定。
- 由于训练RPN网络的时候比较快,作者在第2个epoch的时候开始使用SNIP;而对于分类网络,使用SNIP后每个epoch会增加一倍的训练时间,所以作者在第4个epoch开始使用SNIP。
4.2 SNIP对RPN网络的改善
原本的RPN网络分配正样本的方式是,要么grouth truth与anchor的IOU大于0.7,要么grouth truth与anchor具有最大的IOU。作者发现在COCO数据集中,当使用图像分辨率为800 $\times$ 1200并使用15个anchors(5 scales - 32,64,128,256,512,stride16,3 aspect ratios)的时候,只有30%的grouth truth能够与anchor的IOU大于0.7。在将阈值降低到0.5的时候,也只有58%的grouth truth满足条件,因此有超过40%的grouth truth与anchor的IOU小于0.5被分配为正样本或者被忽略。SNIP由于将所有的目标rescale到一定的尺度范围,使得这个问题得到了一定的改善。另外作者也尝试使用更强的特征以及7个anchor尺度来获得更好的性能,该方式为下文提到的Improved PRN。
4.3 实验结果
4.3.1 SNIP在分类网络上的效果
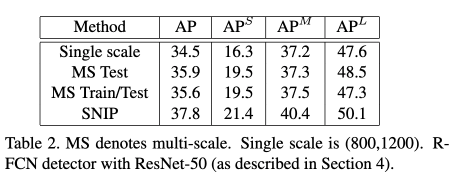
为了验证SNIP应用到分类网络上的效果,作者首先按照第二个探究性实验的网络设置方式,比较了单尺度(800 $\times$ 1200)训练单尺度测试、单尺度训练多尺度测试、多尺度训练多尺度测试及SNIP在COCO数据集上的检出性能。从Table2中可以看出,单尺度训练多尺度测试要比单尺度训练单尺度测试的mAP高出1.4%;多尺度训练多尺度测试相较于单尺度训练多尺度测试并没有提高反而略微下降,这是因为在高分辨率的情况下,网络的感受野不够大,无法去区分大目标;SNIP要比单尺度训练多尺度测试高出1.9%,并且作者只使用了单尺度下的proposals结果,然后将该尺度下的结果映射到其它多个尺度来进行分类。
4.3.2 SNIP在RPN网络上的效果
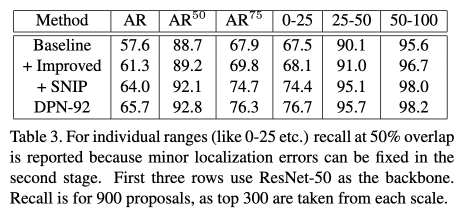
为了验证SNIP应用到RPN网络上的效果,作者使用ResNet-50的conv4特征图来训练RPN网络,并在3种分辨率下进行测试。在每种分辨率下,作者选择top300个proposals来计算平均召回率,3种分辨率共900个proposals。从table3可以看出,Improved版本(Improved版本是指使用更强的特征和更多的anchor尺度(7vs5))要比baseline的平均召回要好,这里大部分的提高来自于大尺度(>100像素)目标召回的提高。但是对于IOU为0.5的平均召回率提高并不明显,IOU为0.5的目标可以通过下一步的分类来得到更加精确的分类和定位,所以IOU为0.5的平均召回率这个指标对两阶段的目标检测更加重要。相对于Improved版本,SNIP将IOU为0.5的平均召回提高了2.9%,小目标的平均召回更是提高6.3%。在使用更强的网络结构DPN-92的情况下,平均召回更是得到了进一步的提高。
4.3.3 与最先进目标检测器的比较
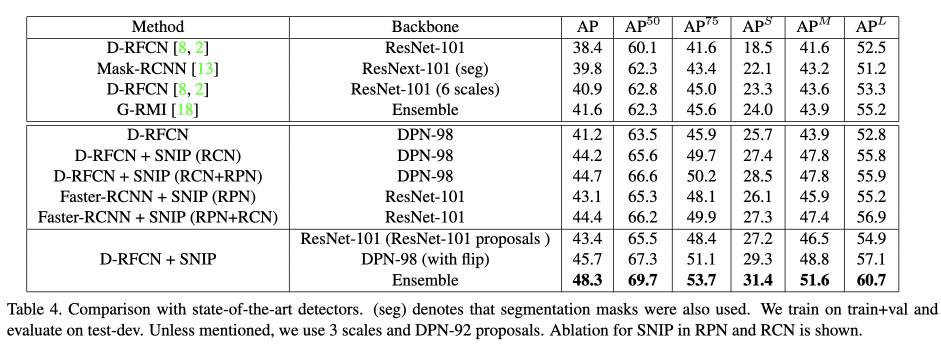
Table4给出了在结合SNIP之后,最先进的目标检测方法的效果。从Table4可以看出在最先进的目标检测方法的基础上结合SNIP,整体的mAP得到了很大的提升。相较于以ResNet-101作为backbone,在单尺度下训练的D-RFCN,该方式为baseline(3尺度测试),在使用SNIP进行训练和测试后,平均AP提高5%,小目标的AP提高8.7%。相较于使用6种尺度测试的baseline,平均AP提高2.5%,小目标的AP提高3.9%。在使用DPN-98作为backbone的情况下性能得到了更进一步的提高。在模型融合的时候,作者使用了backbone为DPN-92的RPN网络的候选结果,并将同个候选目标的预测结果进行求和取平均来得到最终的预测结果。D-RFCN+SNIP(backbone为DPN-98 with flip)这里则是对翻转和没翻转的结果进行求和取平均,来得到预测结果;最后作者使用soft-NMS过滤掉冗余的目标。所有的预训练模型都是在ImageNet-1000分类任务上进行预训练的,模型融合的时候没有用到Faster RCNN。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2018_An Analysis of Scale Invariance in Object Detection - SNIP_CVPR2018(oral)_SinghB_DavisL
文章字数:6.1k
本文作者:xieweihao
发布时间:2018-12-22, 08:16:27
最后更新:2020-02-23, 17:33:03
原始链接:http://weihaoxie.com/post/b4229735.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

