2016_Wide Residual Networks_BMVC2016_ZagoruykoS_KomodakisN
一、背景及意义(动机)
虽然deep residual networks随着深度的提高可以提高性能,但是提高一个百分点的准确率,网络层几乎要增加一倍,这样的话会导致网络参数很大,而使训练缓慢;另外之前对于residual networks的研究主要集中在网络深度和激活函数的顺序方面,还没有对其它方面进行探索。为此,作者对ResNet blocks的宽度进行研究,并在此基础上提出一个新颖的网络结构,wide residual networks(WRNs),该网络结构通过增加网络的宽度,降低网络深度的方式来提高网络的性能。作者通过实验验证了WRNs要比thin且深的网络结构效果要好,效率要高,并证明了deep residual network的主要表达能力来自于residual block。另外作者也研究了dropout对WRNs的影响,作者发现将dropout放在residual blocks的两个卷积层之间,在某些数据集上能达到更好的效果(这个应该跟数据集的复杂度有关)。作者只使用16层的WRNs就在CIFAR数据集上达到了比1000层的deep residual networks更好的效果;只使用50层的WRNs就在ImageNet上取得了比152层的resnet更好的效果,并且在同等准确率的情况下,WRN的速度要比深层的resnet要快上很多倍。
代码:https://github.com/szagoruyko/wide-residual-networks
二、使用什么方法来解决问题(创新点)
重要结论:
- 通过合适的方式增加宽度带来的收益会比增加深度要多,但是只有宽度和深度达到一定比例时才能得到最优的效果。
- 提出了一个新的使用dropout的方式,将dropout放在两个卷积层中间可以更好的在训练中避免过拟合从而提高性能,这个对于数据量较少,复杂度较低的任务可能有用。
三、方法介绍
Fig1给出了WRNs和普通的residual net简单的图示。这里作者使用的residual block为pre-activation的方式,并且只使用了最基本的结构,即包含两个3x3的卷积层。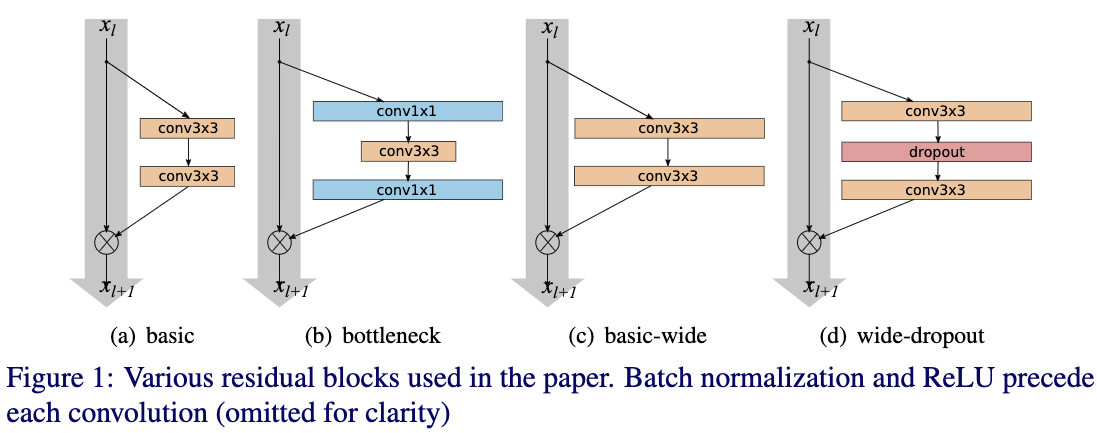
Tabel1给出了作者提出的WRNs的通用结构。这里首层是固定的,而从conv2到conv4则可以通过改变宽度的尺度因子k来增加宽度,也可以通过改变每个组的residual block数N来增加深度。因此不同深度和宽度的WRN可以表示为WRN-n-k,这里的n表示卷积层的总数,k表示宽度的比例因子。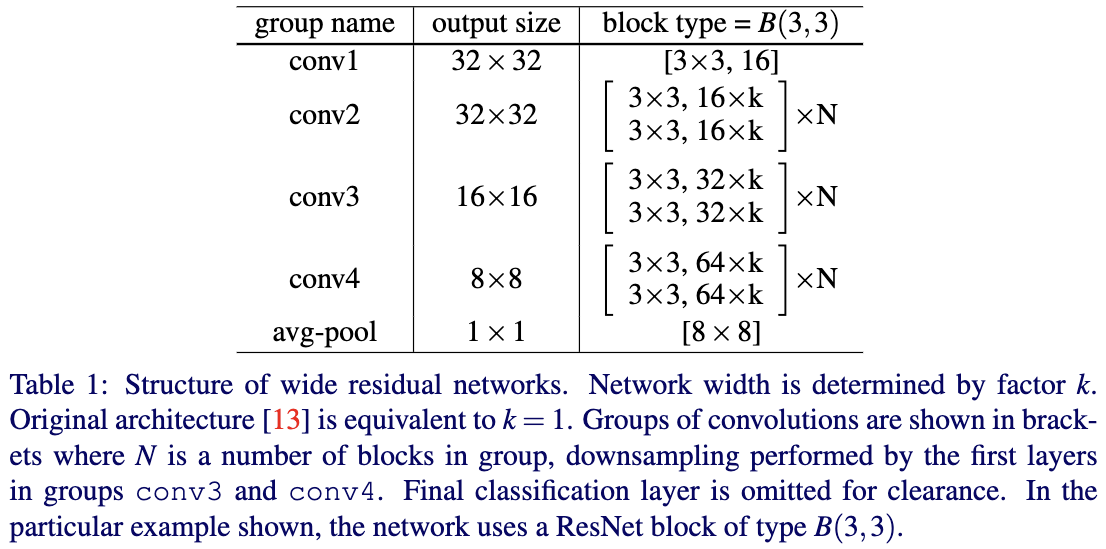
四、实验探究
4.1 对residual block中不同的卷积层类型的探究
为了探究residual block的表达能力对性能的影响,作者对比了不同的residual block形式,主要residual block中卷积层的组合方式。具体的组合方式如下:
Table2给出了不同的residual block的性能。为了让模型复杂度一致,这里B(1,3,1),B(3,1),B(1,3)作者采用WRN-40-2;B(3,3)作者采用WRN-28-2-B(3,3);B(3,1,3)作者采用WRN-22-2。从Table2可以看出两个3x3效果是最好的。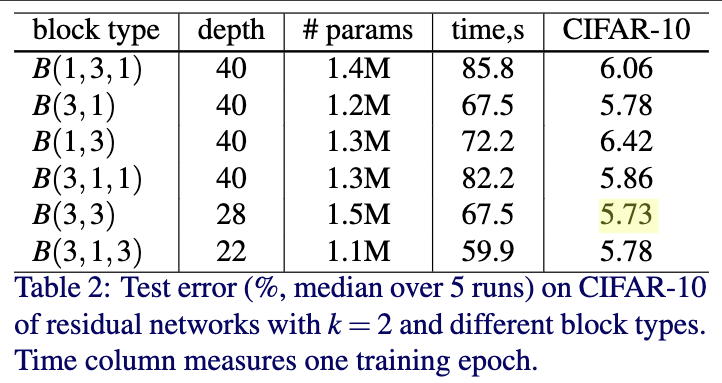
4.2 对residual block中卷积层的数量的探究
为了探究residual block中卷积的数量对性能的影响。作者通过控制模型复杂度和总深度不变的情况下,改变block数以及block中的卷积层数。
Table3比较了residual block中卷积层数量对性能的影响。作者使用的是WRN-40-2,block中只使用3x3的卷积层,并尝试不同的深度因子$l=[1,2,3,4]$。从Table3可以看出,在模型复杂度一定的情况下,block中的层数为2效果最好。
4.3 对residual block宽度的探究
Table4给出了不同深度和宽度在CIFAR-10和CIFAR-100上的效果。从Table4中可以看出,当深度在40、22和16的情况下,性能随宽度的增加而增加;当宽度因子为8和10时,性能随深度的增加而增加。但是从中也可以看出,虽然宽度是影响性能的重要的因素,但是并不是宽度越宽越好,要权衡好宽度和深度。这样才能达到最优的结果。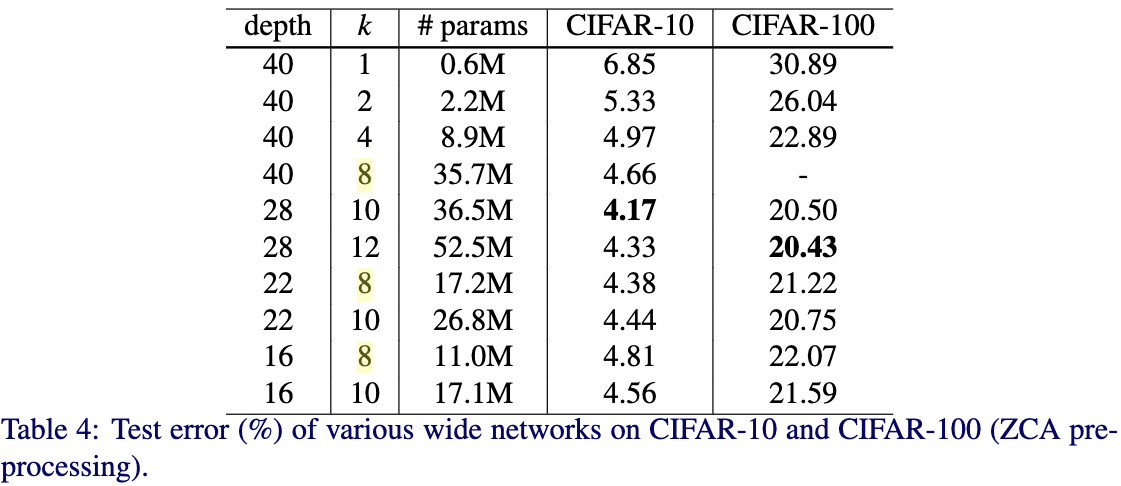
Table5给出了提到的网络结构与最先进的方法在CIFAR-10和CIFAR-100数据集上的性能的对比结果。从Table5中可以看出,WRN要比其他网络结构效果更好,特别是WRN-28-10在CIFAR-10和CIFAR-100数据集上要比ResNet-1001误差分别降低0.92%和3.46%。训练曲线如Figure2所示。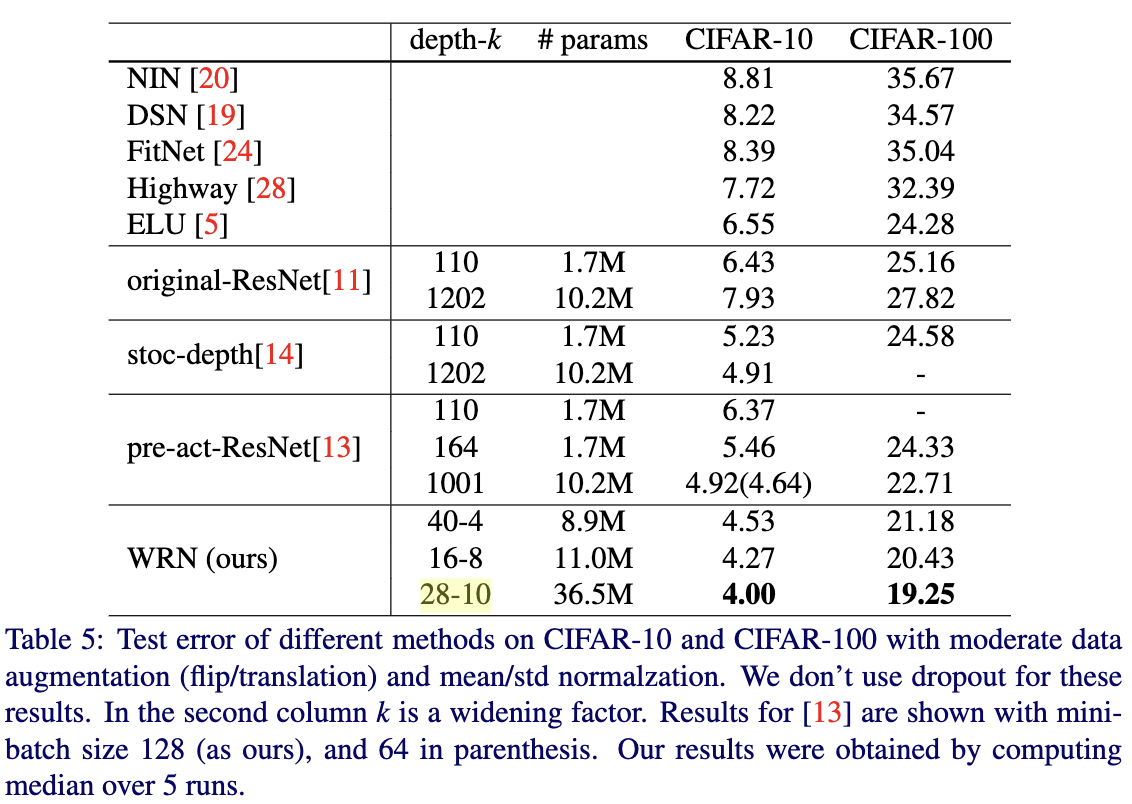
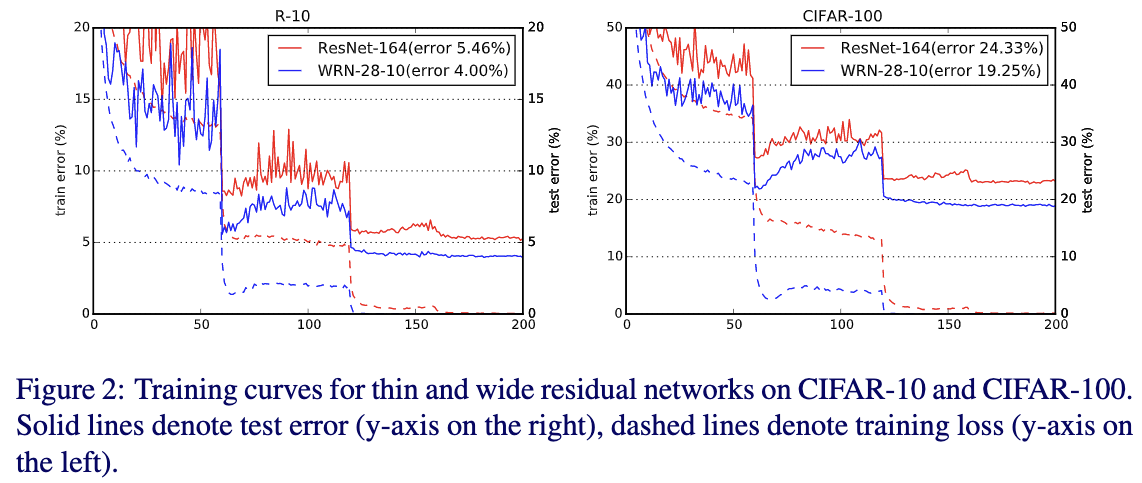
4.4 探究在residual blocks中添加dropout层对效果的影响
Table6给出了在CIFAR-10,CIFAR-100和SVHN数据集上插入dropout和不插入dropout的效果对比。可以看出除了在CIFAR-10数据集下使用WRN-16-4并插入dropout会带来略微的下降,其它情况都得到了一致的提升,这个下降可能是由于模型参数较少。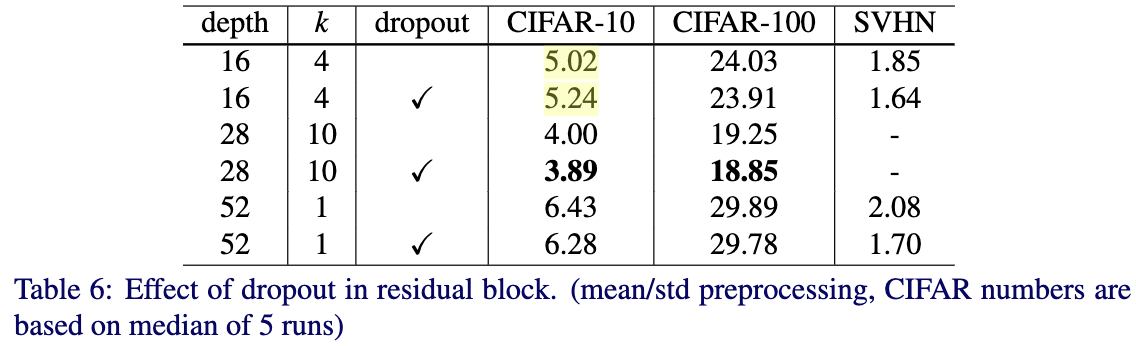
Fig3给出了训练的loss曲线,可以看出resnet在训练的时候,在第一次学习率衰减的时候会出现loss摆动比较厉害的情况,直到下次学习率衰减之后达到稳定。这个主要是由于权重衰减带来的,但是减小权重衰减系数会使得最终效果下降。这里有个有趣的现象就是插入dropout后可以消除这种情况。从Fig3中也可以看出这里dropout主要充当正则项的作用。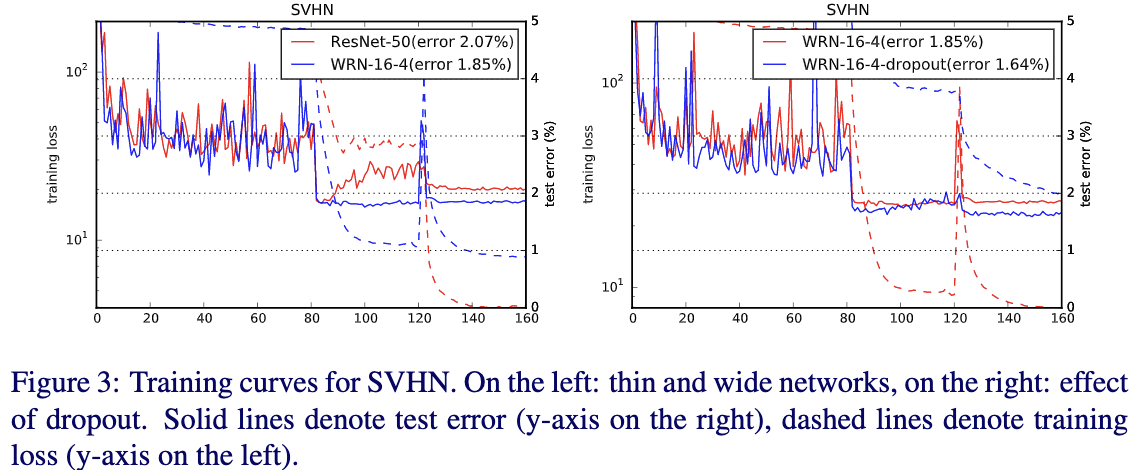
五、实验结果
Table7为non-bottleneck ResNet-18和ResNet-34在ImageNet上的效果。从Table7可以看出随着宽度的增加,性能也跟着提高。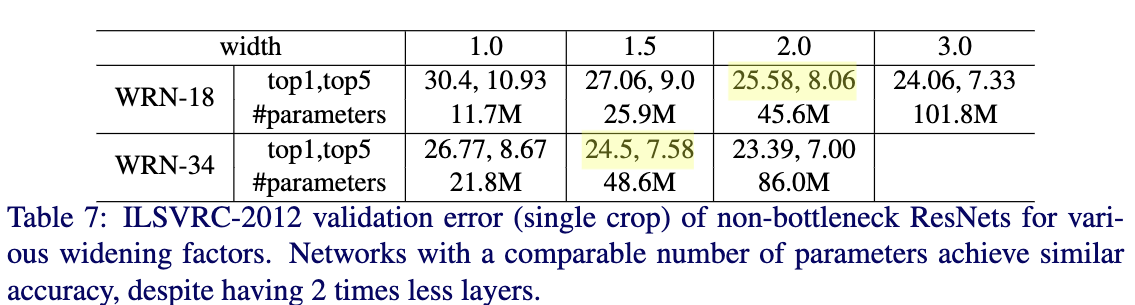
Table8位bottlenect ResNet-50在ImageNet上的效果。从Table8看出,不像在CIFAR,在ImageNet数据集上,使用更深的网络要比浅层网络要好,可能是在任务复杂性方面ImageNet要比CIFAR复杂很多。从Table8也可以看出在同等复杂度下,WRN-50-2-bottleneck与pre-ResNet-200效果接近,但是速度要快很多。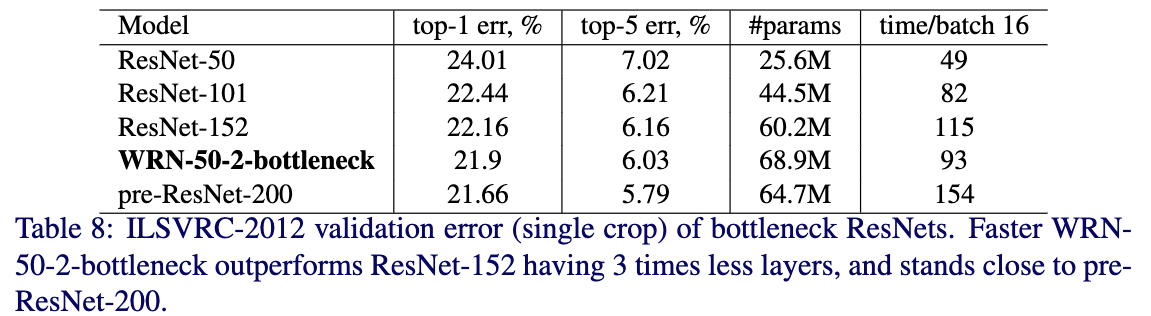
作者也使用了WRN-34-2作为backbone,并组合MultiPathNet和LocNet,测试了WRN在COCO2016目标检测任务效果。虽然只有34层,但是最终的效果要比ResNet-152和Inception-v4效果要好。Table9给出了在各个数据集上,作者试验的不同设置下的WRN中能达到的最好的效果。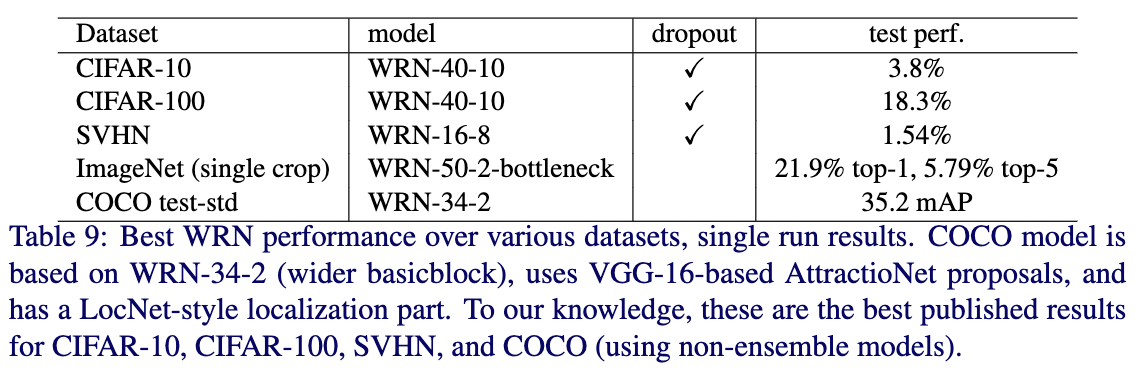
Fig4给出了thin resnet和WRN在相同准确率水平下,推断速度的对比情况。从Fig4可以看出 WRN的速度要快上不少。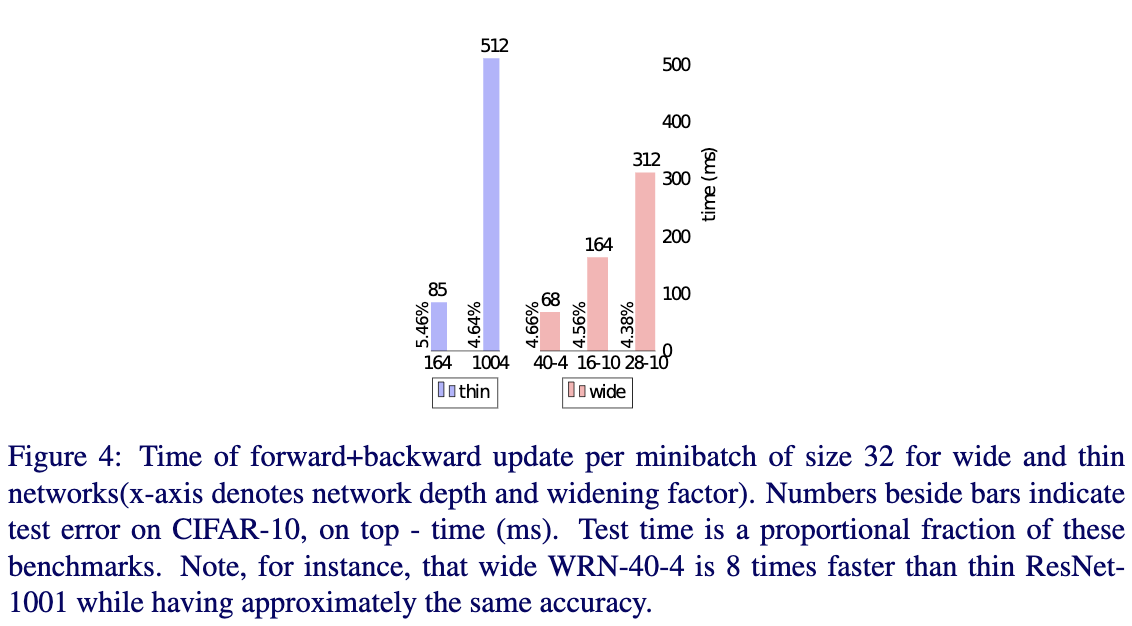
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2016_Wide Residual Networks_BMVC2016_ZagoruykoS_KomodakisN
文章字数:1.7k
本文作者:xieweihao
发布时间:2017-02-05, 12:06:17
最后更新:2020-04-01, 12:37:23
原始链接:http://weihaoxie.com/post/b1aa0dad.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

