2019_ThunderNet: Towards Real-time Generic Object Detection_ICCV2019(Poster)_QinZ et al
一、背景及意义(动机)
基于卷积神经网络的目标检测方法主要包括了两个部分,一个是backbone,另一个是检出部分。对于检出网络的backbone部分,最先进的目标目标检测方法使用很大的网络结构及很大的输入分辨率,这样显然很难达到实时计算的目的。为了实现实时计算,目前大部分实时目标检测方法使用了实时的分类网络作为backbone,但是分类和检测任务是不同的,检测不仅需要大的感受野,也需要获取更加底层的特征,这使得直接使用分类网络作为检出网络的backbone显然不是最优的,并且也很难进行进一步的压缩。对于检出部分,基于cnn的方法一般分成两阶段和一阶段的方法。两阶段的方法,一般使用一个RPN和一个detect head。当前最先进的两阶段检出方法,为了达到更高的准确率,通常会使用一个比较复杂的检出部分,这显然无法用于移动目标检测;light-Head RCNN则采用轻量级的detect head并能达到实时计算的目的,但是当与能实现实时分类的backbone组合的时候,它仍然显得很重,大部分的计算还是在于检出部分,这样也很容易过拟合。一阶段的方法,直接预测类别概率与bbox位置,确实快很多,但是准确率确远低于两阶段方法。那是否两阶段方法,在保持准确率的情况下,能达到更快的计算效率,并能实在移动平台上实现实时推断呢?针对这个思考作者提出了thundernet。作者提出的thundernet,输入的分辨率是320*320;backbone部分使用了改进的shuffeNetV2,作者将其命名为SNet;检出部分,作者沿用了Light-Head R-CNN的设计,并进一步对RPN和R-CNN子网络进行压缩。为了消除由于小的backbone和小的特征图带来的性能下降,作者设计了两个有效的模块:上下文增强模块(CEM)和空间attention模块(SAM)。CEM组合了多个尺度的特征图来使用局部和全局的上下文信息;SAM则使用了从RPN网络学到的特征去精细化ROI区域的特征分布。最后作者调查了输入分辨率,backbone和detection head的平衡关系。作者提到的ThunderNet可以以更低的计算代价,在PASCAL VOC和COCO数据集上可以获得比先前轻量级的一阶段方法更高的准确率。该方法也是第一个可以在达到比较好的精度的情况下在ARM平台进行实时检测的方法。在MobileNet-SSD准确率水平上,ThunderNet可以在ARM平台上每秒跑24.1帧,在x86上每秒跑47.3帧。Fig1给出了ThuderNet与其它最先进的轻量级目标检测方法在准确率和模型大小上的对比情况。从Fig1中可以看出,ThuderNet要比其他方法模型效率更优,效果更好。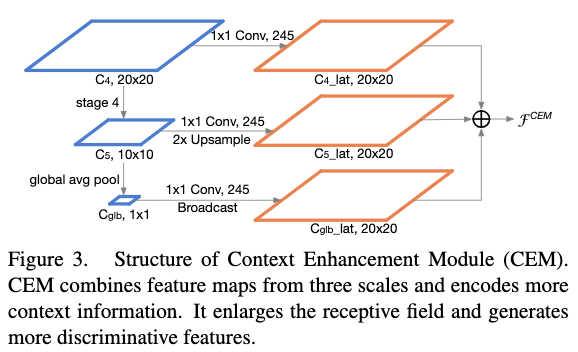
二、使用什么方法来解决问题(创新点)
- 设计了上下文增强模块(CEM)和空间attention模块(SAM),并在light-head R-CNN的基础上,对其进行压缩,得到一个新的能够在ARM上实现实时计算的目标检测器,ThunderNet。该网络在效率和准确率上都要比之前的轻量级目标检测器要好。
- 对现存的各个轻量级的backbone网络进行分析,并将其改进为更加适用于目标检测任务。
- 分析了输入分辨率,backbone和detection head之间的关系。
三、方法介绍
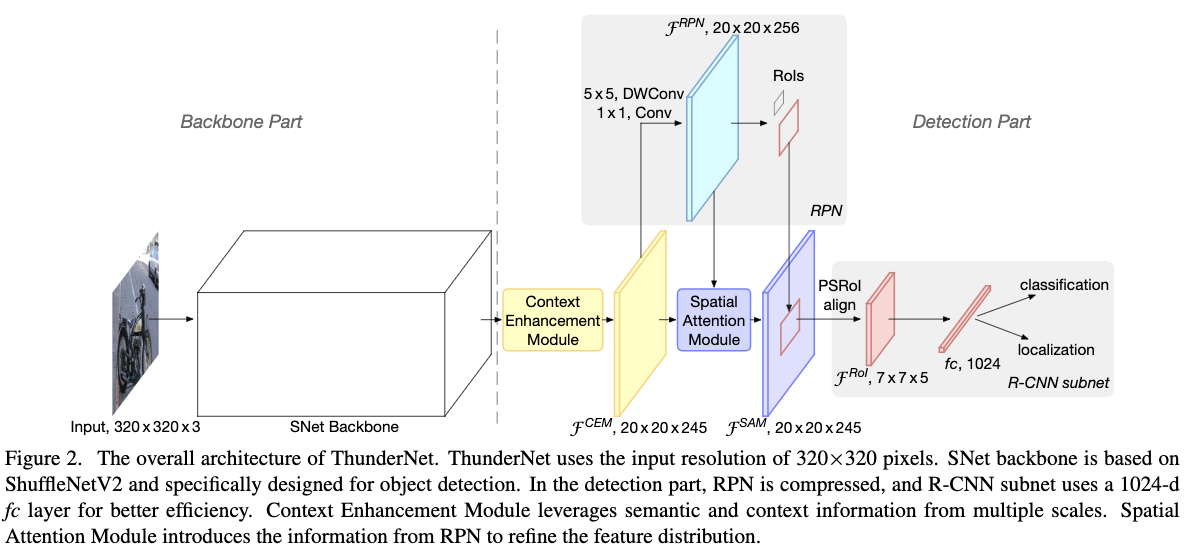
Fig2给出了ThunderNet的整个体系结构。作者提出的thundernet,输入的分辨率是320*320;backbone部分使用了改进的shuffeNetV2,作者将其命名为SNet。检出部分,作者沿用了Light-Head R-CNN的设计,并进一步对RPN和R-CNN子网络进行压缩。为了消除由于小的backbone和小的特征图带来的性能下降,作者设计了两个有效的模块:上下文增强模块(CEM)和空间attention模块(SAM)。CEM组合了多个尺度的特征图来使用局部和全局的上下文信息;SAM则使用了从RPN网络学到的特征去精细化ROI区域的特征分布。
3.1 Backbone Part
输入分辨率
作者发现输入分辨率必须与backbone的能力相匹配,小backbone配大的分辨率或者是小分辨率配大的backbone都不是最优的。为了实现实时推断的目的,作者将输入分辨率设置为320*320。
backbone网络
- 感受野
感受野的大小在cnn网络中扮演重要的角色,因为CNN只能从感受野内获取到信息。大的感受野能够利用更多的上下文信息并且可以有效编码距离较远的像素之间的关系。这个对于定位子任务是很关键的,特别是大目标的定位。先前的工作也阐明了大的感受野对于语义分割和目标检测具有更好的效果。 - 浅层特征和深层特征
在backbone中,浅层特征和深层特征都很重要。浅层特征能获取细节信息,这个对于定位是很关键的;深层特征可以获取更抽象更具有判别性的信息,这个对于分类是很关键的。因此两种类型特征都很重要。在实践中,作者发现对于更大的backbone网络,定位任务比分类任务更加困难,因此浅层特征对于目标检测更加重要;对于小的backbone网络,则会弱化特征表达能力而对定位和分类任务带来负面影响,对于小的backbone网络来说,浅层特征和深层特征都同等重要。
之前ShuffleNetV1/V2约束了感受野;而ShuffleNetV2和MobileNetV2则是缺少浅层特征,Xception则是缺少足够的高层特征。基于对先前实时分类网络的分析,作者在ShuffleNetV2的基础上进行改进,提出用于实时目标检测的backbone网络SNet。作者提出了3个SNet backbone:1)SNet49是为了能达到更快的推断;2)SNet535是为了能达到更高的准确率;3)SNet146则是两者的权衡。作者对ShuffleNetV2的调整方式,首先是将ShuffleNetV2中3X3的逐深度卷积变成5X5的逐深度卷积,计算效率差不多但是增大了网络的感受野(从原来的121到193pixels);然后对于SNet146和SNet535则是将最后Conv5卷积层移除,并扩大浅层特征的宽度,这样可以在没有增加额外计算代价的情况下,深层更多的浅层特征,对于SNet49则是减少Conv5的宽度到512,并增加浅层的宽度,因为网络较浅,如果直接移除的话,backbone无法编码足够多的信息,但是如果把Conv5的宽度全部保留的话,这样浅层的特征又比较弱。Table1给出了backbone的体系结构,这里stage3和stage4(对于Snet49来说则是Conv5)最后的输出特征图在本文中分别被表示为$C_4$和$C_5$。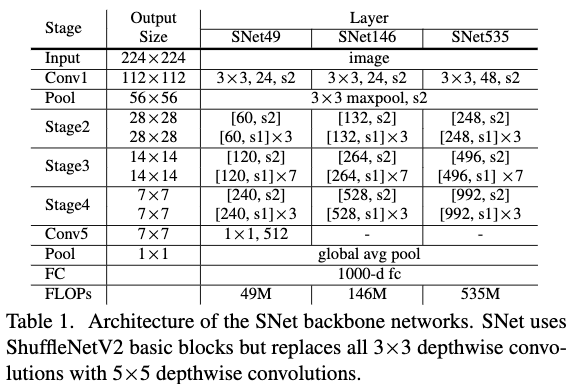
3.2 Detection Part
压缩RPN和detection head
两阶段的目标检测方法通常采用大的RPN网络和很重的检出头,在使用轻量级backbone的情况下,显然是不合适的,既无法实现实时计算也很容易导致过拟合。虽然light-head R-CNN使用轻量级的检出头,但是在使用提到的轻量级的backbone的情况下,仍然过于复杂。为了解决这个问题,作者在light-head R-CNN的基础上对RPN和检出头做进一步的压缩。
对于RPN网络,作者将原先RPN中256个通道的3x3卷积,替换为5x5的逐深度卷积然后再接入一个256个通道的1x1卷积。作者在这里增大了卷积核的大小,以增大感受野和编码更多的上下文信息。anchor主要采用五个尺度{$32^2,64^2,128^2,256^2,512^2$},5个宽高比{$1:2,3:4,1:1,4:3,2:1$}。
对于检出头,原本的light-head R-CNN生成一个小的特征图,channel数为$a \times p \times p$,这里$p=7$是pooling的大小,$a=10$。因为现在使用的backbone和输入的分辨率更加的小,作者将a变成5,从而消除一些冗余的计算。最后作者仍然使用PSROI align去提取每个ROI区域的特征。由于PSROI align提取的特征只有245维,为此作者在之后接入一个1024维的全连接层,用于分类和回归。
CEM
CEM的目的主要是为了增大网络的感受野,以使网络可以编码更多的上下文信息。也可以使用FPN,但是FPN会增加额外的卷积层和多个检出分支,会增加很多计算量。CEM的关键思想是将多个尺度的局部上下文信息和全局上下文信息整合在一起,生成一个更加具有辨别性的特征。在CEM中,最终的特征主要整合了3个尺度的特征信息:$C_4$,$C_5$,$C_{glb}$,这里$C_{glb}$主要是对$C_5$应用全局pooling得到的。在每个特征图上面作者使用一个1x1的卷积层,将通道数变成245,然后再将他们整合到一起。最终的输出特征图大小跟$C_4$一致,为此对于$C_5$需要对其进行upsampled,对于$C_{glb}$则需要对其进行broadcase。通过使用局部和全局的上下文信息,CEM可以有效增大感受野并且可以融合更多细节信息。Fig3给出了提到的CEM结构。
SAM
在通过ROI align去提取每个ROI区域的特征的时候,我们希望特征中背景的信息尽可能小而前景的信息尽可能的大。为此作者利用RPN网络的信息,去精细化特征图中的前背景信息。SAM主要有两个输入:一个是来自RPN网络的特征图$F^{RPN}$,另一个是来自CEM的特征图$F^{CEM}$。输出的特征图$F^{SAM}$可以定义为: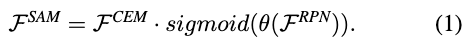
Fig4给出了SAM的结构。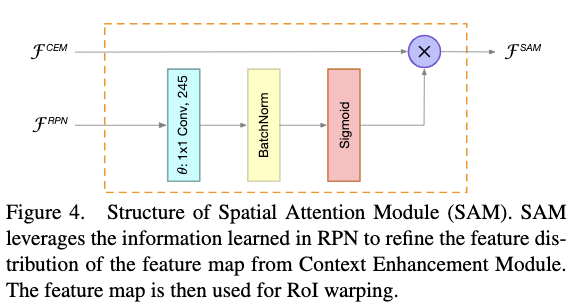
SAM主要有两个功能:一个是精细化前背景信息分布;另一个是增强RPN的训练,因为通过这种方式,R-CNN的信息会传到RPN网络中,从而有助于RPN网络的训练。
四、实验结果
4.1 ThunderNet与最先进方法的比较
Table2给出了ThunderNet在PASCAL VOC目标检测任务上与其它最先进的轻量级一阶段目标检测方法及最先进的目标检测方法的对比结果。从Table2中可以看出,ThunderNet可以以更低的计算代价,得到比其它轻量级一阶段目标检测方法更优的检出性能。另外ThunderNet也可以以更低的计算代价,达到与最先进的目标检测方法如YOLOv2、SSD321、R-FCN同等水平的性能。说明ThunderNet不仅速度快,而且准确率也高。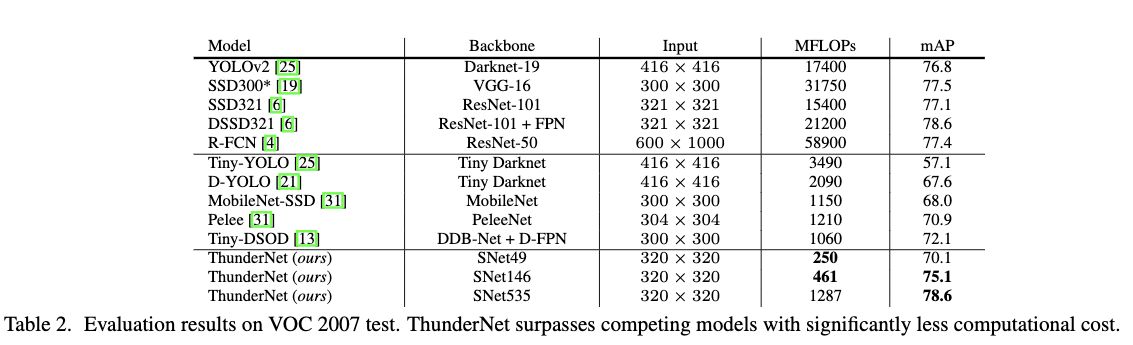
Table3给出了ThunderNet在MS COCO目标检测任务上与其它最先进的轻量级一阶段目标检测方法及最先进的目标检测方法的对比结果.从Table3中可以看出,ThunderNet同样可以以更低的计算代价,得到比其它轻量级一阶段目标检测方法更优的检出性能。另外ThunderNet也可以以更低的计算代价,达到与最先进的目标检测方法如YOLOv2、SSD321、R-FCN同等水平的性能。说明ThunderNet不仅速度快,而且准确率也高。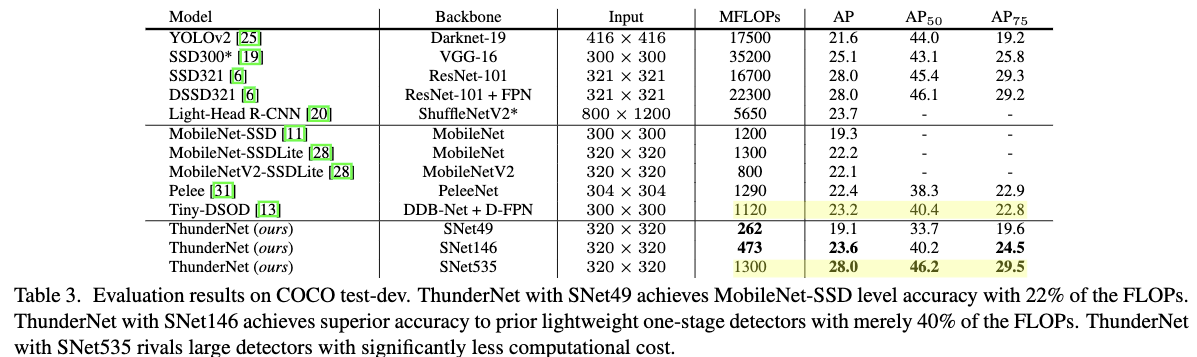
4.2 探究性试验
4.2.1 探究输入分辨率与backbone的关系
Table4给出了不同的backbone在不同的输入分辨率下的效果。从Table4可以看出,大的网络配小的输入分辨率或者小的网络配大的输入分辨率都不是最优的。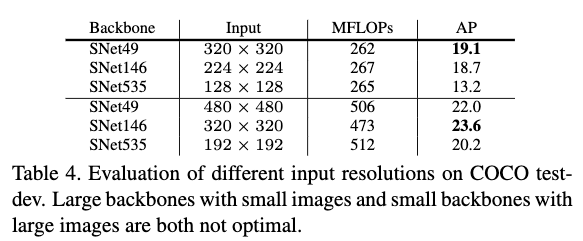
4.2.2 探究backbone网络中不同的设计对性能的影响
Table5给出了不同的设计在ImageNet分类任务和COCO检出任务上的性能。在Table5中,(b)为将SNet146中的5x5逐深度卷积替换为3x3的逐深度卷积,并稍微增加stage2到stage4的通道数,这个改变给分类和检出任务都带来了性能的下跌。说明大的感受野都有助于提高分类和检出任务的性能。(c)为在每个构建块中的第一个1x1卷积层前面加入一个3x3的逐深度卷积层,通道数保持不变,这个改变使得检出任务出现下跌,分类任务基本保持不变。因为两个3x3的卷积层基本跟一个5x5的卷积层的感受野一样,这说明5x5的卷积层的有效感受野要比两个3x3要大。(d)为在SNet146中插入1024通道的Conv5卷积层,然后稍微降低早期阶段的通道数,这个改变使得分类任务性能提高,但是检出任务性能下降。这是因为加入的Conv5卷积层,带来了更加具有判别性的特征,从而提高了分类的准确率,但是减少的早期阶段的通道数,使得编码细节信息的能力下降,从而导致目标检测的性能下降。(f)为移除掉SNet49中的Conv5卷积层,并增加stage2到stage4的通道数。这个改变使得分类和检出的性能都出现下降,这是因为移除了Conv5使得输出通道数基本减半了,这使得模型无法去学习足够的信息,也即模型的表达能力不够。(g)为将SNet49中Conv5的通道数增加到1024维度,然后降低早期阶段的通道数,使得整体的计算复杂度保持一致,这个改变提高了分类任务的性能,但是减低了目标检测的性能。这是因为增大了Conv5的通道数,使得模型有更多抽象的特征,这个变化对分类任务有益,但是由于缺少细节信息使得检出性能下降。上面的这几个实验进一步说明,分类任务和检出任务的不同。为了能得到更好的检出性能,应该平衡好抽象特征和细节特征。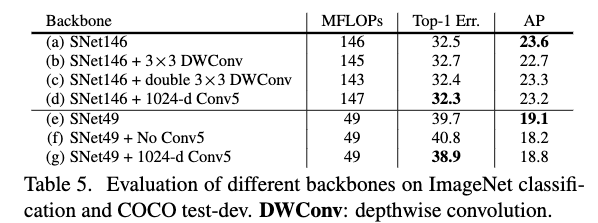
Table6给出了SNet和其它轻量级backbone网络的对比情况。从Table6中可以看出,在相似的计算代价的情况下,SNet146要比其它轻量级的backbone网络在目标检测任务效果更好。这也进一步阐明了作者提出的设计结构的优势。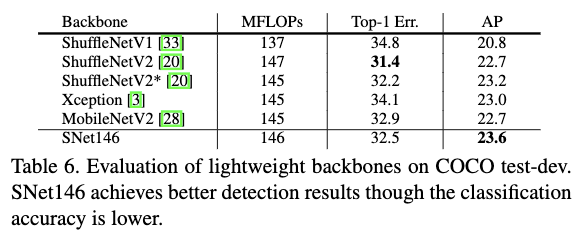
4.2.3 探究Detection部分中不同的设计对性能的影响
Table7给出了检出部分不同的设计在COCO test-dev上的效果。在Table7中,baseline(a)使用了一个压缩了channel的light-head R-CNN,$C_5$特征被upsample到与$C_4$相同的分辨率,两个特征层的输出都为245,然后被分别输入到RPN和RoIwarping分支。RPN网络作者使用了256个通道的3x3卷积层,R-CNN网络作者使用了2048维的fc层。作者在训练过程中也使用了多尺度训练和跨GPU的bn操作以及Soft-NMS后处理。(b)为将RPN网络中的3x3的卷积层替换为5x5的逐深度卷积和一个1x1的卷积层。(C)为在b的基础上,将R-CNN的fc层的节点数减半,变成1024维。通过(b)和(c)两个设计,模型被减小到原来的59%,但是性能基本没有下降,说明原本baseline中存在较多冗余。(d)为在(c)的基础上,加入CEM模块,从Table7中可以看出,该设计带来了性能的提升。(e)为在(c)的基础上,加入SAM模块,从Table7中可以看出,该设计也提高了性能。最后(f)为在(c)的基础上,加入CEM和SAM模块,从Table7可以看出,模型的性能得到了进一步的提升。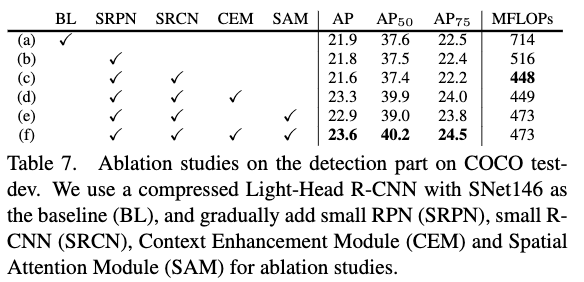
4.2.4 探究backbone和detection head之间的关系
作者使用两个模型进行实验,一个是large-backbone-small-head,另一个是small-head-large-backbone。large-backbone-small-head作者使用了SNet146。small-head-large-backbone则是在使用SNet49的基础上,将$a$变成10,并且将R-CNN的全连接层变成2048维。Table8给出了两个模型在COCO test-dev上的效果,从Table8可以看出,large-backbone-small-head要比small-head-large-backbone要好。
4.2.5 模型推断速度
Table9给出了ThunderNet在Snapdragon 845(ARM)、Xeon E5-2682v4(CPU)和GeForce 1080Ti(GPU)三个运算平台上的推断速度。所有的测试都是只是用单线程。从Table9中可以看出,SNet49可以在ARM和CPU上实现实时计算,这是目前为止在ARM平台上,以单线程跑得最快的实时目标检测器。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2019_ThunderNet: Towards Real-time Generic Object Detection_ICCV2019(Poster)_QinZ et al
文章字数:4.3k
本文作者:xieweihao
发布时间:2020-02-25, 22:34:53
最后更新:2020-04-02, 21:08:35
原始链接:http://weihaoxie.com/post/7e83fc6.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

