2017_Deformable Convolutional Networks_ICCV2017(oral)_DaiJ et al
一、背景及意义(动机)
视觉识别的一个关键的挑战是如何让模型去适应目标的几何变换,如尺度,姿势,视角以及局部的形变,从而让模型对这些信息不敏感。一般为了达到这个目的,有两种方式。一种是构建一个包含目标的各种变换的数据集,从而让模型从这些变换中学习到更加鲁棒的特征,这个通常通过数据增强来实现,但是这种方式通常会增加训练时间;第二种方式是使用对形变不敏感的特征,比如SIFT,然后在目标检测任务中会利用滑动窗口去检测目标。然而上面的这两种方式存在两个缺点,一个是不管是对数据进行增强,还是使用人工设计的特征,增强的方式以及设计特征的方式都考虑了有可能的几何变换形式,当这些方法应用到其它包含其它几何变换的任务的时候,不一定有效;另一个是,人工设计的对几何变换不敏感的特征,不可能十全十美。CNNs在视觉识别任务中取得了很大的成功,如图像分类、语义分割、目标检测等。但是CNNs仍然存在上面说的两个缺点,CNNs模型仍然是通过数据增强,复杂模型的强大表达能力,以及人工设计好的模块来建模目标的几何变换信息,maxpooling只能去适应小的几何变换。CNNs本身的结构限制了模型去适应那些大的未知的几何变换。这个主要是由于CNNs模块的几何结构是固定的:卷积单元每次都按照固定的位置去采样输入特征图;池化层每次都按照同等的比例去减少空间分辨率;RoI池化层每次都将一个RoI区域分离成固定大小的多个bin。这些固定的结构让模型缺少处理几何变换的内部机制。由于卷积神经网络的构建块的几何结构固定,限制了模型去建模目标几何信息变换的能力。而对于语义分割和目标检测任务,让模型去适应几何变换对性能的提高是很关键的。比如深层的语义特征会编码目标的尺度,形变等信息,但是由于每个位置的感受野都是固定的,无法根据目标类型去调整感受野,从而无法学习到更加精确的信息,这个对需要精细化定位的任务影响是比较大的,比如语义分割;另外对于目标检测,现在仍然是按照固定的方式从bbox提取预定义大小的多个bin,这对于非刚性目标来说,显然无法从精确的位置提取精确的特征。为了应对这个问题,作者提出了两个新的构建块,用于增强卷积神经网络学习几何变换的能力,这两个构建块分别为可变形的卷积层和可以变形的RoI池化层。这两个构建块都源自于同个想法,就是通过从任务中学习每个采样位置的偏置,这里不需要增加额外的监督信息,并利用该偏置重新调整采样的位置,使得采样位置从固定变成不固定,这也是为啥叫可变性卷积和可变性RoI池化的原因。由于新加的结构不会对原本的模型结构带来影响,所以可以对任意一个普通的卷积层或者RoI pooling层进行增强,并且可以进行端到端的训练,作者将使用提到的增强结构的网络,称为可变形的卷积神经网络。最后作者在语义分割和目标检测任务上验证了提到的方法的有效性。

二、使用什么方法来解决问题(创新点)
- 为了解决CNNs模型结构固定而无法适应目标较大的几何变换的问题,作者对卷积层和ROI池化层进行增强,提出了可变形卷积和可变形的ROI池化层。
- 可变形卷积和可变形的ROI池化层,主要是通过学习各个采样位置的偏置信息,来让卷积层和ROI池化层的采样位置从原本固定的方式,变成自适应目标几何信息的形式,从而极大的提高对精细化的特征比较依赖的任务,如目标检测和语义分割。
三、方法介绍
3.1 Deformable Convolution
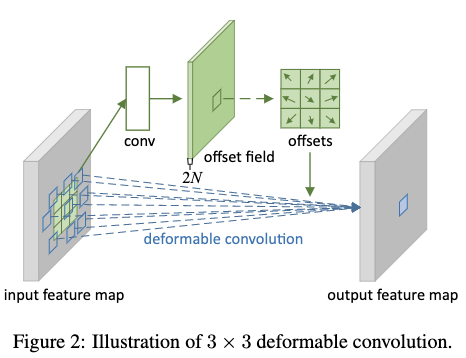
Deformable Convolution其实就是通过学习卷积核在输入特征图上各个采样位置的偏置,然后通过将学习到的偏置与原本采样位置相加来改变原本的采样位置,让采样位置可以适应目标的几何变换。学习到的每个输入位置的偏置一般都是浮点数类型,这样得到的新位置也是浮点数类型,得到新的采样位置一般没办法与输入特征图上的特征点相对应,所以这里作者采用双线性差值来得到新位置的特征点。如Fig2所示,偏置的获取主要是通过一个放置在输入特征图上的卷积层来得到,学习偏置的卷积层的卷积核与应用偏置的卷积层的卷积核的大小和dilation rate相同。学习偏置的卷积层输出的feature map的分辨率与输入的feature map一致,只是channel数扩大了一倍,因为每个位置对应x和y两个方向。不管是学习偏置的卷积层还是应用偏置的卷积层,都是通过将梯度反向传播到双线性差值来同时学习的。
3.2 Deformable ROI Pooling
这里作者给出了普通ROI Pooling和PSRoI Pooling的Deformable形式。不管是哪种信息,都是可用通过反向传播进行端到端的训练。
3.2.1 RoI Pooling的Deformable形式
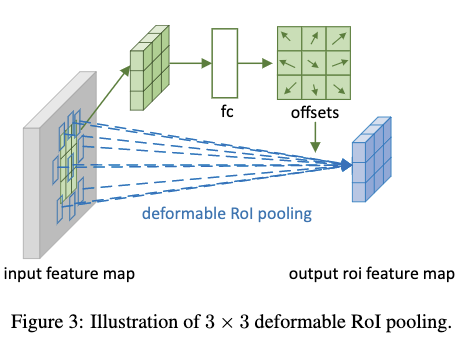
类似于Deformable Convolution,Deformable RoI Pooling也是学习各个输入位置的偏置,但是与其不同的是它学习的是映射到每个bin上的各个特征块的偏置。由于偏置是浮点数,新的特征块的获取也是通过双线性插值来得到。如Fig3所示,标准化后的偏置信息是通过在原本RoI Pooling的feature map上应用一个fc层来得到的。在得到标准化后的偏置信息之后再让每个偏置的x,y方向分别乘以ROI的宽和高,然后再乘以一个预定义的尺度因子来得到最终的特征块的偏置,作者将尺度因子设置为0.1。这里通过学习标准化后的偏置信息而不是原始偏置信息是很有必要的,这样可以消除RoI大小的影响,使得学习更加容易。
3.2.2 PsRoI Pooling的Deformable形式
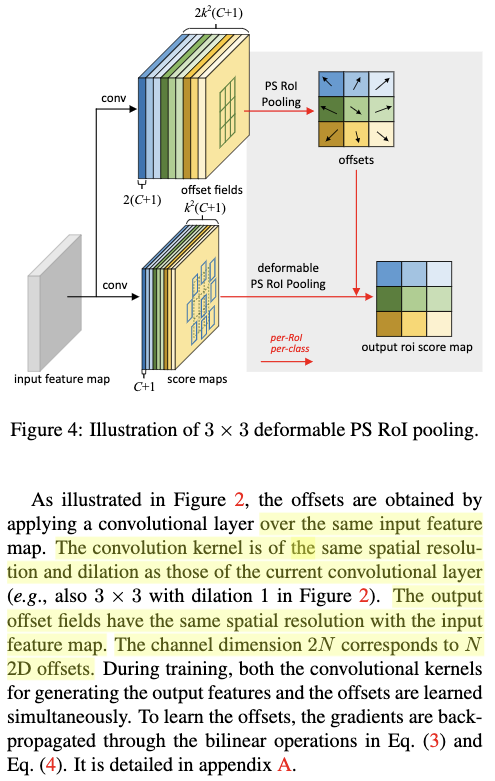
这里Deformable PsRoI Pooling与Deformable RoI Pooling是类似的,只是Deformable PsRoI Pooling的偏置是通过与PsRoI Pooling一致的全卷积形式学习到的。如Fig4所示,标准化后的偏置信息是通过与原本一致的位置敏感得分图来得到的,只是由于偏置有两个方向,为此这里的channel数是原本的2倍;并且每个位置的标准化的偏置信息来自于与之对应的score map。最后在得到标准化后的偏置信息之后,再按照Deformable RoI Pooling的方式,得到最终的偏置信息。
3.3 Deformable ConvNet
这里不管是Deformable Convlution还是Deformable RoI Pooling都是在原本的基础上增加卷积层来学习偏置信息,没有改变原本的结构,输入输出也是与原来的一致,所以可以将任意的普通卷积层和RoI Pooling层替换为Deformable形式。训练的时候学习偏置信息的卷积层和fc层的相关权重都被初始化为0,学习率被设置为原本学习率的$\beta$倍,默认是1,在faster R-CNN框架下fc层则是被设置为0.01。替换了Deformable Convolution和Deformable RoIPooling的CNNs这里称为Deformable ConvNet。
为了将Deformable ConvNet应用到最先进的网络结构中,并让其适用不同的任务。作者对要使用的最先进的网络结构做了一些调整。作者发现不管是什么任务,都可以将整个网络划分成两个阶段,第一个阶段是一个层数很深的全卷积网络,用于生成特征;第二个阶段则是一个浅层的任务指向的网络,用于生成结果。为此作者分别就这两个阶段对网络进行调整。
在第一阶段中作者使用两个最先进的网络结构用于特征提取,ResNet-101和一个修改版本的Inception-ResNet(因为之前Inception-ResNet用于图像分类,存在特征不对齐的问题,所以作者根据Aligned-Inception-Resnet进行更改)。这两个网络首先在ImageNet分类任务上进行预训练,然后后作者将最后的average Pooling层和fc层移除掉;最后加入一个随机初始化的1x1卷积层,将最后的卷积层压缩到1024个channel。为了增加最后卷积层的分辨率,作者将Conv5的第一个卷积层的stride从2变成1,从而将整体的stride从32变成16,为了补偿感受野的变小,Conv5中所有卷积核大于1x1的卷积层的dilation rate全部重1变成2。这里作者将deformable Convolution应用到最后几个卷积核大于1x1的卷积层上。
在第二阶段中语义分割作者采用DeepLab语义分割方法,目标检测作者采用了Category-Aware RPN,Faster R-CNN和R-FCN目标检测方法。
- 为了应用DeepLab语义分割方法,作者在特征提取网络输出的feature map上加了一个1x1的卷积层,生成一个(C+1)的feature map,表示每个像素属于不同类别的得分,最后应用一个softmax层得到每个像素属于不同类别的概率。
- Category-Aware RPN是与RPN类似的方法,与RPN网络的区别主要是最后输出的不是2分类,而是(C+1)个类别。
- 为了应用Faster R-CNN方法,作者将RPN网络加在conv4的顶端,而RoI Pooling层则是被加在了最后输出的feature map上,然后再接两个fc层,最后再bounding box回归器和分类器。
- 为了应用R-FCN方法,作者按照原先的实现方式,在最后生成一个位置敏感得分图。
四、实验结果及重要结论
这里作者测试了提到的方法在语义分割任务和目标检测任务上的效果。语义分割任务主要使用了PASCAL VOC数据集和CityScapes数据集,并使用mIoU来评估分割的效果。目标检测任务主要使用了PASCAL VOC以及COCO数据集,并使用mAP来评估检出的效果。对于PASCAL VOC给出的是IOU阈值大于0.5和IOU阈值大于0.7的mAP,对于COCO则是给出IOU阈值大于0.5小于0.95的mAP。
4.1 探究提到的两个模块对语义分割和目标检测的性能的影响
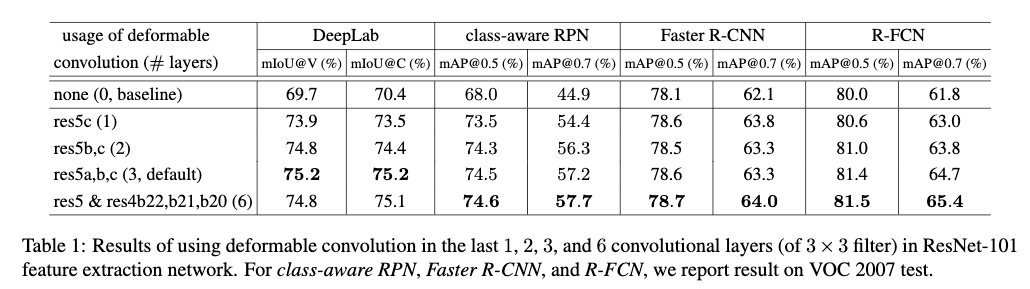
Table1给出了将deformable Convolution应用在最后的1、2、3和6个卷积核大于1x1的卷积层上的效果。从Table1中可以看出,随着deformable convolution的数量不断提高,性能稳步提升。对于DeepLab来说当使用3个deformable Convolution的时候性能就饱和了,而对于其它任务使用6个则效果更好。在后面的实验作者都使用了3个deformable Convolution。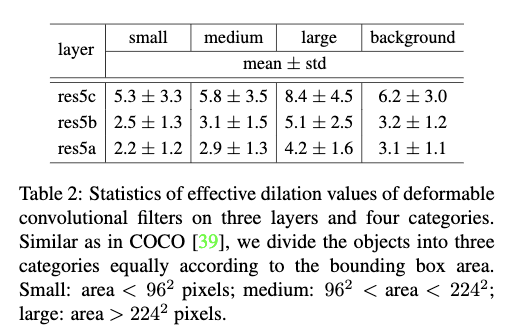
Table2给出了将使用3个Deformable Convolution的R-FCN网络应用到VOC2007测试集上,并将Deformable Convolution的filters根据ground truth bounding box的标注以及filters中心所在的位置分成4个类别,small、medium、large和background,给出了每个类别下filters的dilation的均值和方差。从Table2中可以看出:1)deformable convolution的filters对应的感受野大小与目标的大小是相关的。deformable convolution可以很好适应目标的几何变换;2)背景的dilation大小是介于medium和large目标的中间的,说明为了更好的识别背景,应该使用一个相对大的感受野。这个观察在不同层上的表现是一致的。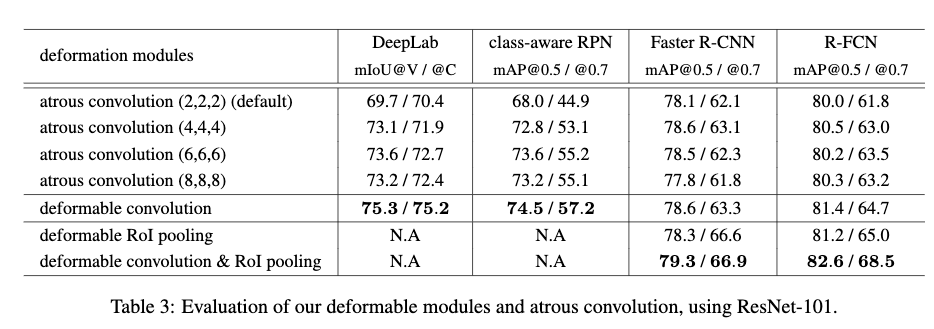
Table3给出了对ResNet-101的最后3个3x3的卷积层使用不同dilation rate的效果,以及在dilation rate为2的情况下使用deformable convolution和deformable RoI pooling的效果。从Table3可以看出:1)随着dilation rate的增加,各个任务的性能不断提高,这也说明默认网络的有效感受野比较小;2)对于不同的任务来说,最优的dilation rate是不同的,对于DeepLab来说其最优的dilation rate是6,而对于Faster R-CNN则是3;3)使用deformable convolution效果是最好的,这说明让filter自适应去学习偏置是有效而且必要的;4)单独使用deformable RoI Pooling也带来了很大的提升,特别是mAP@0.7,当结合deformable Convolution的时候,性能得到了更进一步的提高。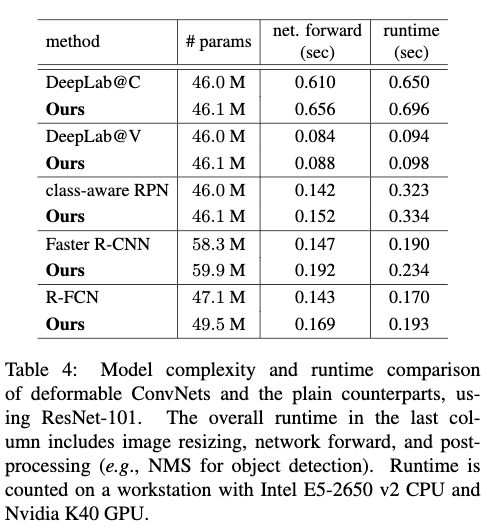
Table4给出了各个模型的deformable版本和原来版本的模型复杂度和运行时间。从Table4可以看出,deformable ConvNets相较于原来的版本只是增加了极少了模型参数和极少的计算量,这说明性能的提高不是因为模型复杂度的增加,而是来自于模型建模几何变换的能力的增加。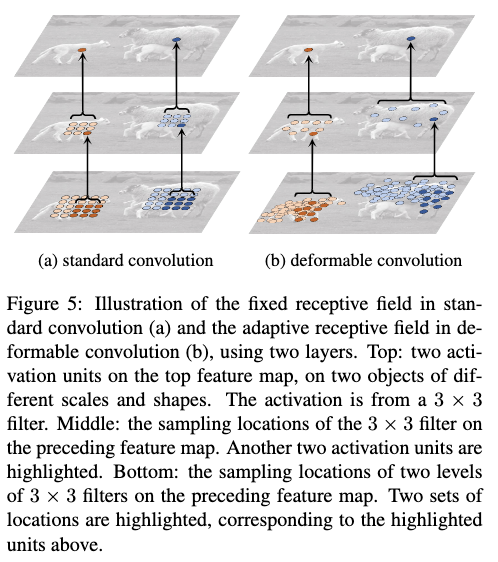


Fig5、Fig6、Fig7给出了应用Deformable Convolution和Deformable RoI Pooling后的一个直观效果。从Fig5、Fig6、Fig7可以看出,Deformable Convolution和Deformable RoI Pooling可以更好地适应不同目标的大小和形变,从而去关注更加有效的信息。
4.2 deformable ConvNet在COCO目标检测任务的效果
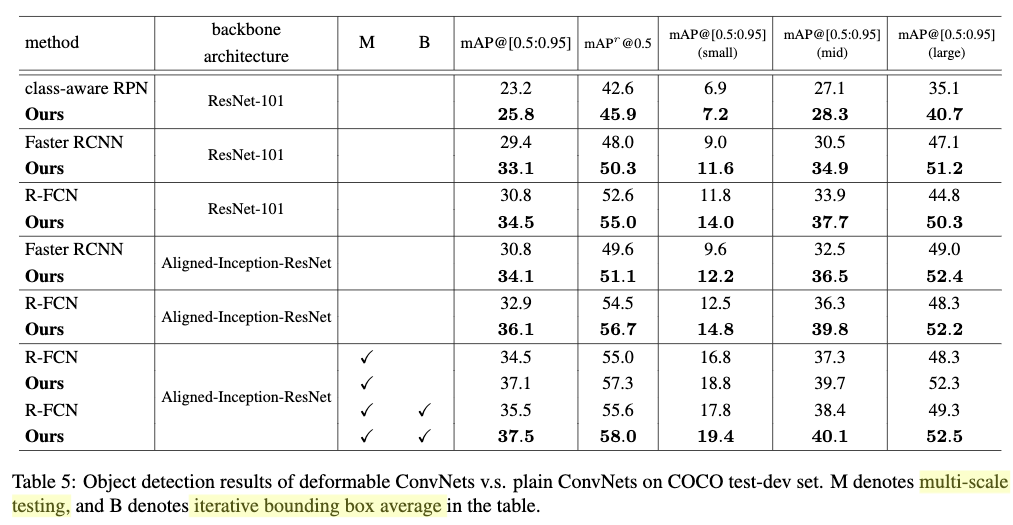
Table5对比了deformable ConvNet与原来版本在COCO目标检测任务上的效果。从Table5可以看出,1)不同的方法其deformable ConvNet版本要比原版本效果要好;2)在使用表达能力更加强的特征提取网络,以及多尺度测试和iterative bounding box average的情况下,效果得到了更进一步的提高。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_Deformable Convolutional Networks_ICCV2017(oral)_DaiJ et al
文章字数:3.7k
本文作者:xieweihao
发布时间:2018-03-02, 09:02:20
最后更新:2020-03-02, 09:11:16
原始链接:http://weihaoxie.com/post/992cacb1.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

