2017_Xception:Deep learning with Depthwise Separable Convolutions_CVPR2017_CholletF
一、背景及意义(动机)
普通的卷积可以理解为同时映射通道之间以及空间之间的关系,而Inception模块则是让这个过程更加简单,它首先通过一系列的1X1卷积映射通道之间的关系,将输入数据映射到3到4个分离的空间;然后再通过3X3或者5X5卷积在这些小的3D空间中,映射通道之间和空间之间的相互关系。逐深度分离卷积可以理解为最大化towers的Inception 模块。是不是跨通道的关系和跨空间的关系可以完全解耦,是不是利用逐深度离散卷积替换掉Inception模块效果更好?基于这样的假设作者提出了一个新的网络结构,主要是将Inception模块替换为逐深度分离卷积,作者将其称为Xception。最后作者通过了实验验证该结构的有效性,在同等网络复杂度的情况下,Xception网络在Imagenet数据集上稍微比Inception V3好,并且在更大的数据集上提升效果更加明显。
二、使用什么方法来解决问题(创新点)
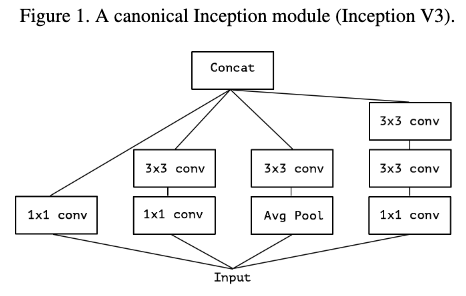
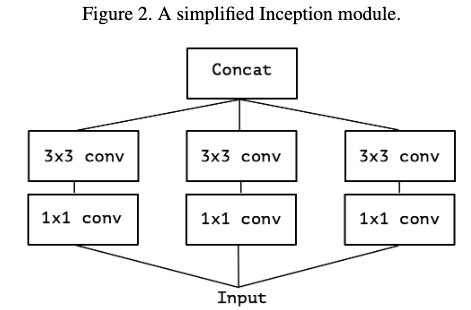
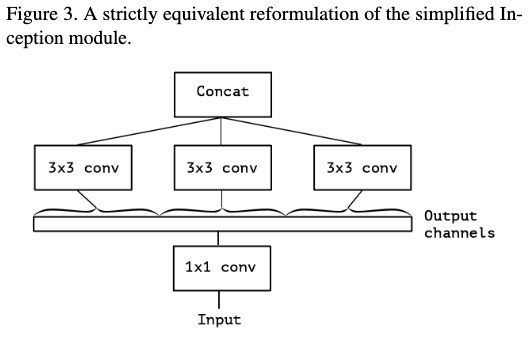
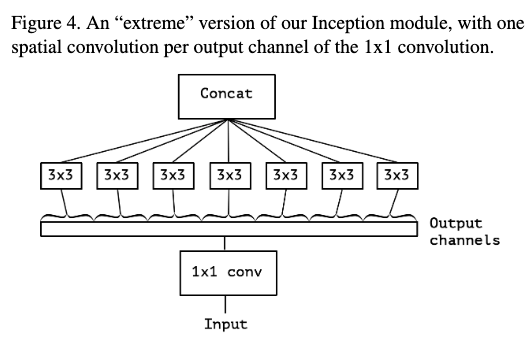
考虑最简单版本的Inception模块,只是用卷积tower,不使用平均tower,如figure2。这样就可以将其看做是一个大的1x1卷积在加上一个group卷积,如figure3。如果这个group达到极限,如figure4,也即每个group只有一个通道,那就是它的极限形式。
这个形式与逐深度离散卷积基本等同。它与逐深度离散卷积的不同之处在于1)计算顺序不同,逐深度离散卷积是先计算逐通道卷积,再利用1X1卷积去计算跨通道卷积。2)逐深度离散卷积在计算逐通道卷积的时候一般不使用非线性函数。第一点一般没有影响,第二点可能对性能有所影响,所以后面作者对此进行了研究。通过这种变换关系,是不是利用逐深度离散卷积替换掉Inception模块更好呢,为此有了这个新的网络结构Xception.在这篇论文中作者只是研究了这种极限形式,而普通卷积和逐通道离散卷积的中间形式是否更好作者并没有进行研究。
三、实现细节
3.1 网络结构
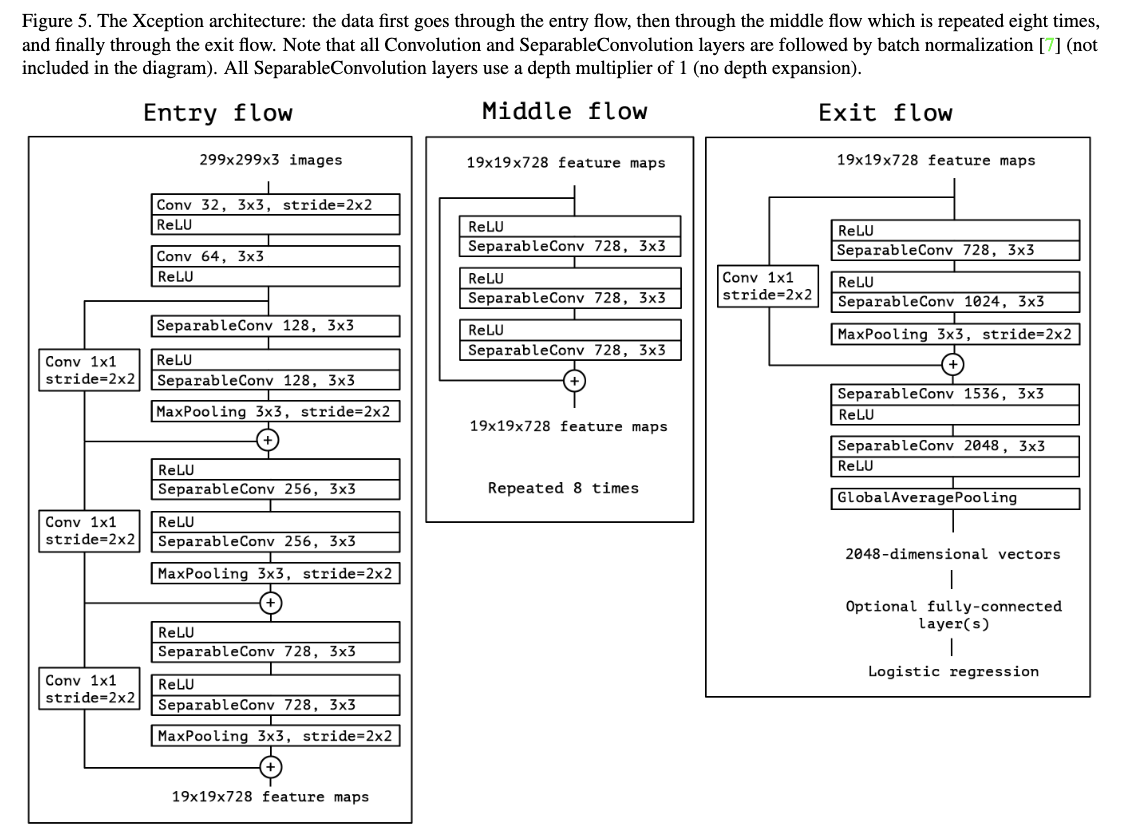
整体的网络结构如figure5所示,整个特征提取网络有36层,最后加入一个逻辑回归分类器。这36层被划分成14个模块,除了第一个和最后一个,每一个都有residual connections。
代码https://keras.io/applications/#xception
四、实验
4.1 模型及数据集说明
由于Inception V3和提到的Xception模型复杂度差不多,所以作者选择了Inception V3来做对比实验。作者在两个任务上做对比试验,一个是ImageNet分类任务,该任务是包含1000个类别的单标签分类任务;另一个是JFT分类任务,该任务是有17000个类别的多标签分类任务。JFT数据集包括了350million张高分辨率的图片,总共类别数为17000个。为了评估模型在JFT上训练的效果,作者使用了另一个辅助数据集FastEval14k来进行评估。该数据集包括14000张图片,共6000个类别,平均每张图片标签数为36.5个。评估方式是使用带权重的MAP@100,这个score主要来自于该图片在社交媒体上出现的频率。
4.2 参数设置
On ImageNet:
- Optimizer: SGD
- Momentum: 0.9
- Initial learning rate: 0.045
- Learning rate decay: decay of rate 0.94 every 2 epochs
On JFT:
- Optimizer: RMSprop
- Momentum: 0.9
- Initial learning rate: 0.001
- Learning rate decay: decay of rate 0.9 every 3,000,000 samples
两个模型在这两个任务上都使用了相同的参数配置,而且这些参数配置是适配于Inception V3的,这就撇开了故意去选择对于Xception更好的参数
正则化:
- weight decay :
Inception V3:4e-5
xception: 1e-5 - Dropout:
Imagenet:0.5 both
JFT: none both - Auxiliary loss:
None
训练平台为60块 K80 GPU
- Imagenet采用同步梯度下降,跑3d
- JFT采用异步梯度下降,跑1个月没完全拟合,完全拟合需要3个月。
4.3 结果比较
4.3.1 分类性能的比较
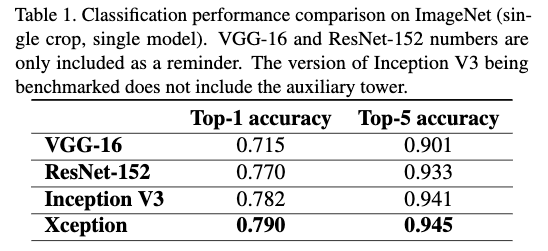

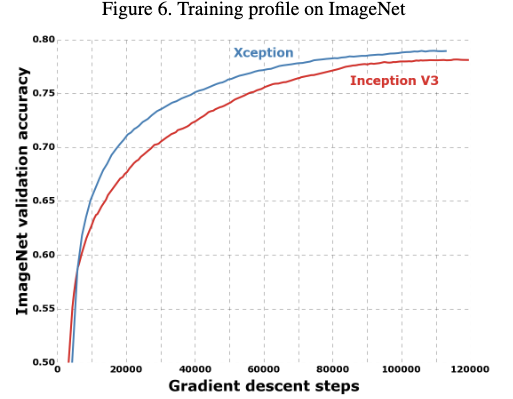
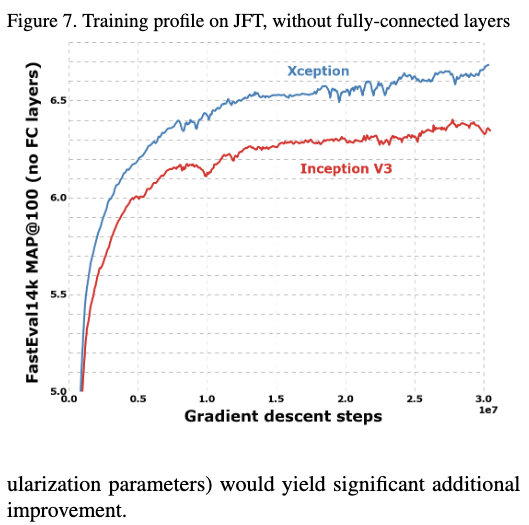
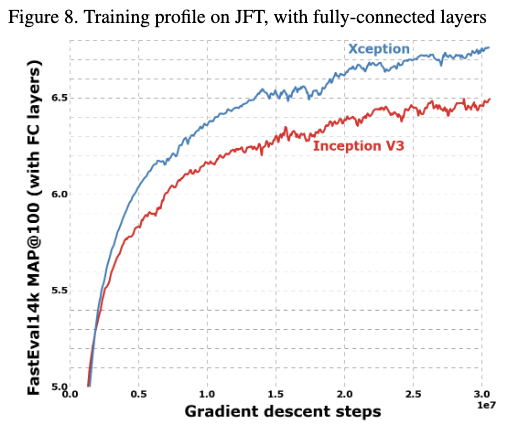
所有的评估都是用单模型单尺度,并且Imagenet任务都是验证集上的结果,JFT的结果是运行了1个月后的结果不是完全拟合的结果。
从结果上可以看到,在这两个任务上,Xception都要优于Inception V3。并且在JFT上,提升更为明显,作者认为这是因为Inception V3的参数更加适配Imagenet分类任务导致的,如果Xception也进行参数的调优,提升效果会更加明显。
4.3.2 模型大小和速度的比较
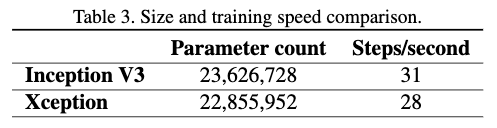
从Table3中可以看出两个模型的大小相似,但是Xception要稍微比Inception V3慢。从模型大小可以看出Xception性能的提升不是来自于模型表达能力的增加,而是来自于逐深度离散卷积带来的性能提升。
4.3.3 residual connetions的影响
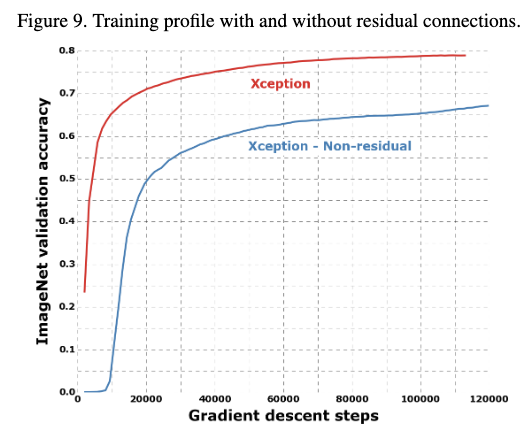
从结果可以看出residual connection确实有助于模型的拟合,不管在速度或者是模型性能,都带来了提升。residual connections只是对于这种网络结构很重要,但是并不是说主要的提升是它。作者也试了在vggnet中加入逐深度离散卷积,在参数数与InceptionV3接近的情况下,在JFT任务上也超过了Inception V3。说明该结构确实有用。
4.3.4 逐通道卷积操作后加入激活函数对结果的影响
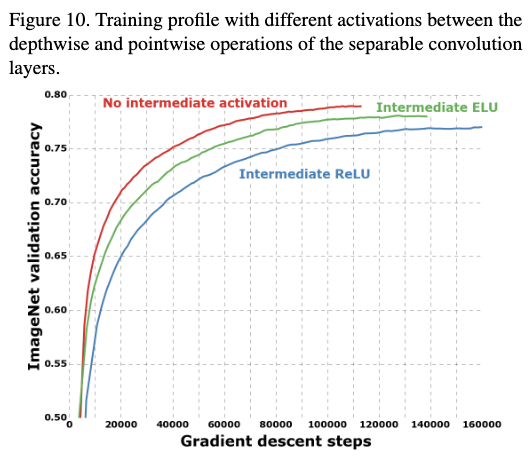
从结果可以看出,在逐通道卷积操作之后不使用任何激活函数,效果是最好的,不管是拟合速度还是分类性能都更好。这可能是对于多通道的卷积使用激活函数更有用,而单通道的卷积不使用激活函数更加有用。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_Xception:Deep learning with Depthwise Separable Convolutions_CVPR2017_CholletF
文章字数:1.6k
本文作者:xieweihao
发布时间:2018-01-18, 16:27:06
最后更新:2020-01-23, 10:15:49
原始链接:http://weihaoxie.com/post/d9144852.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

