2017_Mask R-CNN(ICCV2017)Kaiming He
一、背景及意义(动机)
在这篇论文中,作者对faster rcnn进行扩展,通过在faster rcnn的ROI区域上加多一个分支来做实例分割。加多的一个分支是一个轻量级的分支,使得mask rcnn每秒能跑5帧,而且mask rcnn可以很容易泛化到其他任务,比如人体关键点识别。作者利用mask rcnn在coco的实例分割,目标检测和行人关键点识别3个任务上都取得了最好的结果,在单模型情况下都比其他最先进的模型要好。mask rcnn可以作为实例识别的一个基本框架,在目标检测之后对每个实例进行进一步的识别。
二、使用什么方法来解决问题(创新点)
创新点
- 之前faster rcnn没有设计成像素对齐的方式,主要是RoIPool层只是对ROI区域进行粗糙的空间量化来提取特征,没有精确对齐ROI区域,这样对实例分割结果影响很大。为此作者提出了一个像素对齐的RoIAlign层来保留精确的空间位置信息。虽然这只是一个小的改动,但是对于实例分割的效果影响却很大。
- 作者发现对分类预测和实例分割两个任务进行解耦这一步很关键。作者独立地为每一类目标预测一个2值mask,然后将类别预测放到了RoI分类那个分支。
重要结论
- 更优的网络可以带来最终效果的提高(并不是说所有的任务都可以直接从更优的网络结构中获益的,但是该任务可以)见Table2a;
- 每个类别使用一个2值mask要比多类别mask要好,见Table2b。只使用一个类别无关的mask与每个类别使用一个2值mask差异不大;
- RoIAlign对实例分割具有很大的提升,见Table2c。特别是当使用的特征的stride更大时,更加明显见Table2d。
- mask采用卷积的形式要比采用MLP的形式要好Table2e。
- RoIAlign也有助于目标检测;
- 多任务学习提高了目标检测的效果;
- Mask R-CNN拉近了目标检测和实力分割的性能差异。
- 多任务学习可以提高关键的估计的性能。但是会略微影响实例分割和目标检测的效果。
- ROIAlign对于关键点识别更加重要。
三、方法介绍
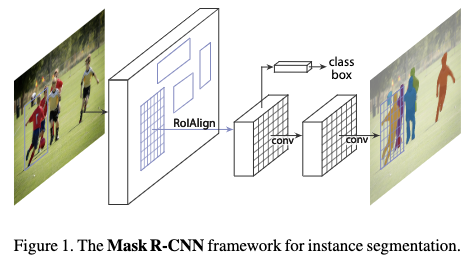
mask R-CNN也采用与Faster R-CNN类似的两阶段方式。第一阶段利用RPN网络预测候选目标;第二阶段并行预测ROI区域的类别、精确的位置以及二值mask。
损失函数
这里的Loss包括3部分,分别是分类loss、回归loss和二值mask loss。
分类loss和回归loss与Faster R-CNN一样。这里输出的mask是每个类别对应一个二值mask,每个mask的大小为$m \times m$,所以每个ROI区域对应$Km^2$维输出,然后再接一个逐像素的sigmoid,最终的mask loss就是平均的二值交叉熵 loss。在训练的时候,只有grouth truth类别对应的mask,才用来训练,其它mask不用于训练。而在预测的时候,则是根据分类分支的类别来选择对应的mask。这种方式与通常的语义分割不同,通常的语义分割使用softmax和多分类的交叉熵去预测每个像素是属于哪个类别的,而这种方式则是将类别与分割预测进行了解耦,作者也通过实验验证了这种方式在实例分割任务中表现更好。
mask的表示
这里作者采用的是卷积的形式,最终输出为$m \times m$的卷积特征图,而不是采用全连接的形式。作者也通过实验验证了通过卷积的形式要比全连接的形式要好。
RoIAlign
原本的ROIPool是利用RPN网络的预测结果,将预测的位置映射到要提取特征的特征图上,然后再根据输出大小,将特征图分成nxn份,最后在每个bin上进行maxpool或者avepool。这里映射的方式只是粗略的进行取整计算,不够精确,这种方式对于分类可能没有影响,因为分类对于这种小的偏移不敏感,但是对于分割,则会很大影响分割的精度,特别是在特征图缩减较大的时候,在特征图上小的偏移会在原图上产生一个较大的偏移。为此作者提出了RoIAlign层,将ROI的位置精确的映射到要提取的特征图上。
- 首先作者将原本取整的运算变成了精确的浮点运算,来找到ROI在特征图上的精确位置;
- 然后根据输出大小将提取的特征图精确地划分成nxn份;
- 接着根据采样个数,bin中的像素点,利用双线性差值得到采样点的值;
- 最后再利用maxPool或者avePool得到每个bin的值。
最后作者通过实验证明了RoIAlign确实要比RoIWarp和RoIPool好。
网络结构
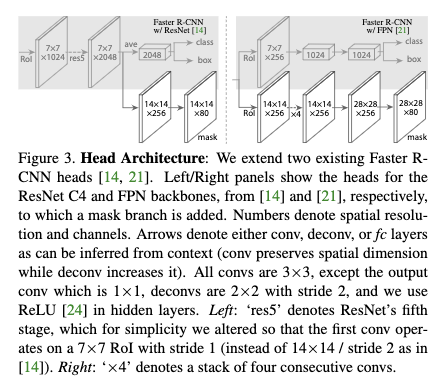
backbone作者主要使用了ResNet-50-C4和ResNet-FPN。这两个backbone对应的head见Figure3.
实现细节
Trainnig:
- 训练mask RCNN(非RPN)的时候,如果候选框与ground-truth的IOU大于0.5则为正样本,否则为负样本。
- $L_{mask}$只定义在正样本上,mask目标是RoI区域和grouth truth交叉的部分
- 超出图像的候选目标都不用于训练
- 将图像的短边resize到800
- 每个mini-batch每个GPU包括2张图片,每张图片有N个候选框,正负样本的比例为1:3。对于ResNet-50-C4backbone作者使用N=64,对于ResNet-FPN作者使用N=512。总共使用8个GPU,因此每个mini-batch有8张图片。
- 总共跑160k个迭代,其实学习率为0.02,到120k个迭代后降为0.002.
- 权重衰减系数为0.0001,动量为0.9
- RPN anchors包括5个尺度,3个宽高比。
- 这里为了方便比较,作者并没有让RPN和mask RCNN共享权重,但是他们是可以共享的。
Inference
- 测试的时候对于backbone为ResNet-50-C4的网络,proposals数是300,对于FPN,proposals数为1000。接着再进行NMS操作;
- 然后再取前100个目标,得到它们的mask,这里只取了预测类别对应的mask;
- 最后mask被resize到RoI区域的大小,并根据阈值为0.5,进行二值化。
- 由于这里只取top100来计算mask,所以只增加了一点点时间,约占对应的faster rcnn模型的20%
四、实验结果
4.1 实例分割和目标检测结果
4.1.1 实例分割
数据集主要使用了COCO数据集,使用trainval-135k作为训练集,minival-5k作为验证集。评价指标包括$AP$, $AP_{0.5}$, $AP_0.75$, $AP_S$, $AP_M$, $AP_L$. 这里AP的是mask IoU。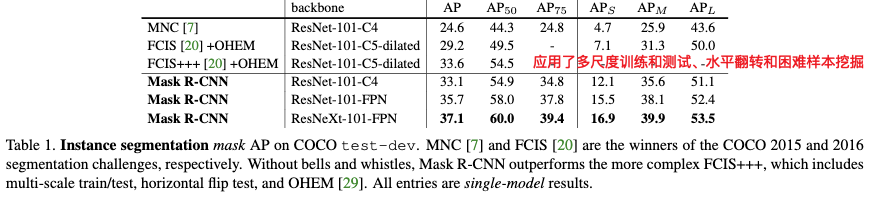



从结果来看mask R-CNN在实例分割任务上要比最先进的方法好很多。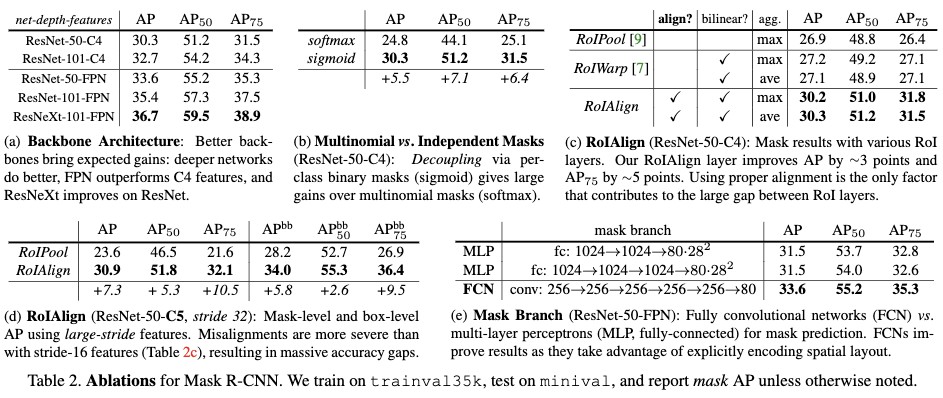
重要结论
- 更优的网络可以带来最终效果的提高(并不是说所有的任务都可以直接从更优的网络结构中获益的,但是该任务可以)见Table2a;
- 每个类别使用一个2值mask要比多类别mask要好,见Table2b。只使用一个类别无关的mask与每个类别使用一个2值mask差异不大;
- RoIAlign对实例分割具有很大的提升,见Table2c。特别是当使用的特征的stride更大时,更加明显见Table2d。
- mask采用卷积的形式要比采用MLP的形式要好Table2e。
4.1.2 目标检测
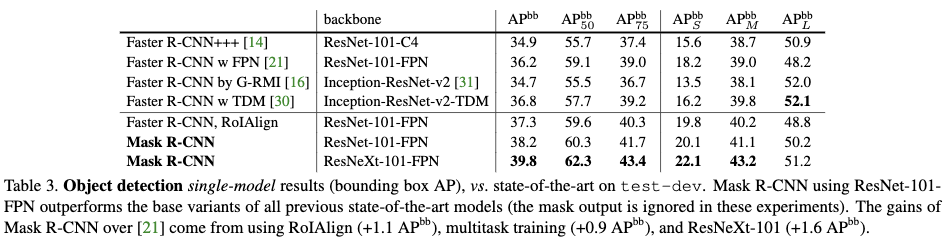
从结果来看mask R-CNN在目标检测任务上要比最先进的方法好很多。
重要结论
- RoIAlign也有助于目标检测;
- 多任务学习提高了目标检测的效果;
- Mask R-CNN拉近了目标检测和实力分割的性能差异。
4.1.3 运行时间
Inference
作者将RPN和mask R-CNN进行特征共享,并按照faster RCNN的方式进行训练。发现最后的结果与不共享基本一样。并且在使用ResNet-101-FPN作为backbone时推断时间为195ms(Tesla M40 GPU)+15ms(cpu);使用ResNet-50-C4则约为400ms。显然ResNet-101-FPN更优更快。
Training
在COCO, trainval-135k数据集上,使用8个GPU(每个mini-batch16张图片0.72s),ResNet-50-FPN只需要32个小时;ResNet-101-FPN只需要44个小时。
4.2 人的关键点估计
实现细节
作者将关键点位置以 one-hot的形式表示,并使用mask R-CNN去预测K个masks,每个mask表示一种关键点类型(比如左肩膀,右手肘等),即训练的目标是一个one-hot的$m\times m$的二值mask,里面只有一个位置被标记为前景,其它都为背景。训练时使用的loss,是K维的softmax with loss(使用softmax可以确保一个位置只有一种类型的关键点),每个ROI共$m^2$个样本。
关键点识别的Head architecture与以FPN作为backbone的实例分割任务的Head architecture类似。它主要由8个核为3x3通道为512的卷积层和一个转置卷积层以及一个2x的双线性差值层构成,最后的输出为56X56。作者发现对于关键点识别,最后输出的分辨率对关键点定位影响很大。
模型主要使用了COCO的trainval-135k数据集中包含关键点的数据来训练,由于数据集比较小,所以作者使用了尺度增强方式,将图片随机缩放到[640,800],测试的时候则使用尺度为800来测试。前60k次学习率为0.02,60k到80k学习率为0.002,80k后学习率为0.0002,共训练90k次迭代。在使用nms的时候作者使用的IOU阈值为0.5,其它细节与mask-rcnn一样。
实验结果
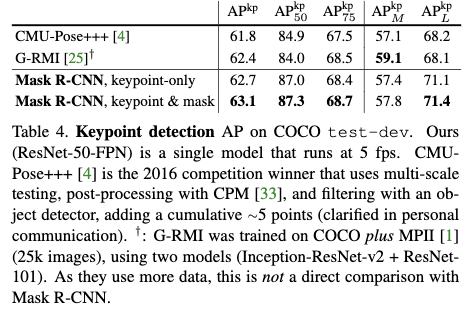
从结果来看mask R-CNN在关键点估计任务上要比最先进的方法好很多。
重要结论
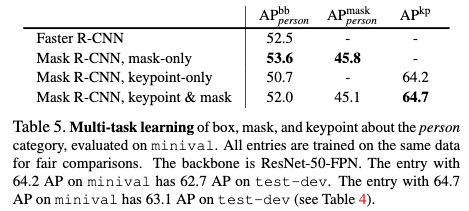
- 多任务学习可以提高关键的估计的性能。但是会略微影响实例分割和目标检测的效果。

- ROIAlign对于关键点识别更加重要。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 524813168@qq.com
文章标题:2017_Mask R-CNN(ICCV2017)Kaiming He
文章字数:2.6k
本文作者:xieweihao
发布时间:2018-01-15, 21:43:03
最后更新:2020-01-23, 10:21:36
原始链接:http://weihaoxie.com/post/f80ddd8e.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

